| Oracle9i Database Performance Tuning Guide and Reference Release 2 (9.2) Part Number A96533-02 |
|





|
View PDF |
| Oracle9i Database Performance Tuning Guide and Reference Release 2 (9.2) Part Number A96533-02 |
|
|
View PDF |
This chapter describes how to identify high-resource SQL statements, explains what should be collected, and provides tuning suggestions.
This chapter contains the following sections:
The objective of tuning a system is either to reduce the response time for end users of the system, or to reduce the resources used to process the same work. You can accomplish both of these objectives in several ways:
This is what commonly constitutes SQL tuning: finding more efficient ways to process the same workload. It is possible to change the execution plan of the statement without altering the functionality to reduce the resource consumption.
Two examples of how resource usage can be reduced are:
Systems often tend to have peak usage in the daytime when real users are connected to the system, and low usage in the nighttime. If noncritical reports and batch jobs can be scheduled to run in the nighttime and their concurrency during day time reduced, then it frees up resources for the more critical programs in the day.
Queries that access large amounts of data (typical data warehouse queries) often can be parallelized. This is extremely useful for reducing the response time in low concurrency data warehouse. However, for OLTP environments, which tend to be high concurrency, this can adversely impact other users by increasing the overall resource usage of the program.
This section describes the steps involved in identifying and gathering data on poorly-performing SQL statements.
The first step in identifying resource-intensive SQL is to categorize the problem you are attempting to fix: is the problem specific to a single program (or small number of programs), or is the problem generic over the application?
If you are tuning a specific program (GUI or 3GL), then identifying the SQL to examine is a simple matter of looking at the SQL executed within the program.
If it is not possible to identify the SQL (for example, the SQL is generated dynamically), then use SQL_TRACE to generate a trace file that contains the SQL executed, then use TKPROF to generate an output file.
The SQL statements in the TKPROF output file can be ordered by various parameters, such as the execution elapsed time (exeela), which usually assists in the identification by ordering the SQL statements by elapsed time (with highest elapsed time SQL statements at the top of the file). This makes the job of identifying the poorly performing SQL easier if there are many SQL statements in the file.
Oracle SQL Analyze can be used for identifying resource intensive SQL statements, generating explain plans, and evaluating SQL performance. Figure 6-1 is an illustration of SQL Analyze displaying the SQL statement used in Example 1-3, "Using EXPLAIN PLAN".
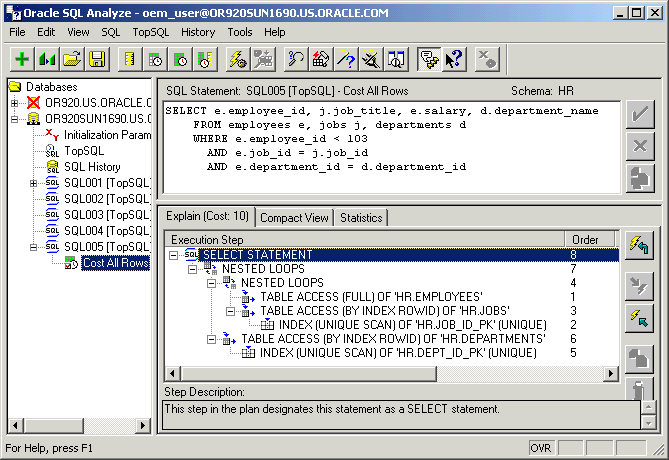
Text description of the illustration sqlanalyze1.gif
| See Also:
For more information on Oracle SQL Analyze, see the Database Tuning with the Oracle Tuning Pack manual |
If your whole application is performing suboptimally, or if you are attempting to reduce the overall CPU or I/O load on the database server, then identifying resource-intensive SQL involves the following steps:
V$FILESTAT), system statistics (V$SYSSTAT), and SQL statistics (V$SQLAREA or V$SQL, V$SQLTEXT and V$SQL_PLAN).
| See Also:
Chapter 21, "Using Statspack" for information on how to use Statspack to gather Oracle instance performance data for you |
V$SQLAREA. V$SQLAREA contains resource usage information for all SQL statements in the shared pool. The data in V$SQLAREA should be ordered by resource usage. The most common resources are:
One method to identify which SQL statements are creating the highest load is to compare the resources used by a SQL statement to the total amount of that resource used in the period. For BUFFER_GETS, divide each SQL statement's BUFFER_GETS by the total number of buffer gets during the period. The total number of buffer gets in the system is available in the V$SYSSTAT table, for the statistic session logical reads.
Similarly, it is possible to apportion the percentage of disk reads a statement performs out of the total disk reads performed by the system by dividing V$SQL_AREA.DISK_READS by the value for the V$SYSSTAT statistic physical reads. The SQL sections of the Statspack report include this data, so you do not need to perform the percentage calculations manually.
| See Also:
Chapter 24, "Dynamic Performance Views for Tuning" for more information on |
After you have identified the candidate SQL statements, the next stage is to gather information that enables you to examine the statements and tune them.
If you are most concerned with CPU, then examine the top SQL statements that performed the most BUFFER_GETS during that interval. Otherwise, start with the SQL statement that performed the most DISK_READS.
The tuning process begins by determining the structure of the underlying tables and indexes.
Information gathered includes the following:
V$SQLTEXTEXPLAIN PLAN, V$SQL_PLAN, or the TKPROF output)The purpose of dynamic sampling is to improve server performance by determining more accurate selectivity and cardinality estimates. More accurate selectivity and cardinality estimates allow the optimizer to produce better performing plans.
You can use dynamic sampling to:
The primary performance attribute is compile time. Oracle determines at compile time whether a query would benefit from dynamic sampling. If so, a recursive SQL statement is issued to scan a small random sample of the table's blocks, and to apply the relevant single table predicates to estimate predicate selectivities. The sample cardinality can also be used, in some cases, to estimate table cardinality.
Depending on the value of the OPTIMIZER_DYNAMIC_SAMPLING initialization parameter, a certain number of blocks are read by the dynamic sampling query.
For a query that normally completes quickly (in less than a few seconds), you will not want to incur the cost of dynamic sampling. However, dynamic sampling can be beneficial under any of the following conditions:
Dynamic sampling can be applied to a subset of a single table's predicates and combined with standard selectivity estimates of predicates for which dynamic sampling is not done.
You control dynamic sampling with the OPTIMIZER_DYNAMIC_SAMPLING parameter, which can be set to a value from 0 to 10.
0 means dynamic sampling will not be done.1 (the default) means dynamic sampling will be performed if all of the following conditions are true:
Dynamic sampling is repeatable if no rows have been inserted, deleted, or updated in the table being sampled.
The parameter OPTIMIZER_FEATURES_ENABLE turns off dynamic sampling if set to a version prior to 9.0.2.
| See Also:
"DYNAMIC_SAMPLING" for details about using this hint |
This section describes ways you can improve SQL statement efficiency:
The CBO uses statistics gathered on tables and indexes when determining the optimal execution plan. If these statistics have not been gathered, or if the statistics are no longer representative of the data stored within the database, then the optimizer does not have sufficient information to generate the best plan.
Things to check:
DBA_TABLES.NUM_ROWS. If there is significant data skew on predicate columns, then consider using histograms.When tuning (or writing) a SQL statement in an OLTP environment, the goal is to drive from the table that has the most selective filter. This means that there are fewer rows passed to the next step. If the next step is a join, then this means that fewer rows are joined. Check to see whether the access paths are optimal.
When examining the optimizer execution plan, look for the following:
SELECT list to see whether access to the view is necessary.Consider the predicates in the SQL statement and the number of rows in the table. Look for suspicious activity, such as a full table scans on tables with large number of rows, which have predicates in the where clause. Determine why an index is not used for such a selective predicate.
A full table scan does not mean inefficiency. It might be more efficient to perform a full table scan on a small table, or to perform a full table scan to leverage a better join method (for example, hash_join) for the number of rows returned.
If any of these conditions are not optimal, then consider restructuring the SQL statement or the indexes available on the tables.
Often, rewriting an inefficient SQL statement is easier than repairing it. If you understand the purpose of a given statement, then you might be able to quickly and easily write a new statement that meets the requirement.
To improve SQL efficiency, use equijoins whenever possible. Statements that perform equijoins on untransformed column values are the easiest to tune.
Use untransformed column values. For example, use:
WHERE a.order_no = b.order_no
rather than:
WHERE TO_NUMBER (SUBSTR(a.order_no, INSTR(b.order_no, '.') - 1)) = TO_NUMBER (SUBSTR(a.order_no, INSTR(b.order_no, '.') - 1))
Do not use SQL functions in predicate clauses or WHERE clauses. Any expression using a column, such as a function having the column as its argument, causes the optimizer to ignore the possibility of using an index on that column, even a unique index, unless there is a function-based index defined that can be used.
Avoid mixed-mode expressions, and beware of implicit type conversions. When you want to use an index on the VARCHAR2 column charcol, but the WHERE clause looks like this:
AND charcol = numexpr
where numexpr is an expression of number type (for example, 1, USERENV('SESSIONID'), numcol, numcol+0,...), Oracle translates that expression into:
AND TO_NUMBER(charcol) = numexpr
Avoid the following kinds of complex expressions:
These expressions prevent the optimizer from assigning valid cardinality or selectivity estimates and can in turn affect the overall plan and the join method.
Add the predicate versus using NVL() technique.
For example:
SELECT employee_num, full_name Name, employee_id FROM mtl_employees_current_view WHERE (employee_num = NVL (:b1,employee_num)) AND (organization_id=:1) ORDER BY employee_num;
Also:
SELECT employee_num, full_name Name, employee_id FROM mtl_employees_current_view WHERE (employee_num = :b1) AND (organization_id=:1) ORDER BY employee_num;
When you need to use SQL functions on filters or join predicates, do not use them on the columns on which you want to have an index; rather, use them on the opposite side of the predicate, as in the following statement:
TO_CHAR(numcol) = varcol
rather than
varcol = TO_CHAR(numcol)
| See Also:
Chapter 4, "Understanding Indexes and Clusters" for more information on function-based indexes |
SQL is not a procedural language. Using one piece of SQL to do many different things usually results in a less-than-optimal result for each task. If you want SQL to accomplish different things, then write various statements, rather than writing one statement to do different things depending on the parameters you give it.
It is always better to write separate SQL statements for different tasks, but if you must use one SQL statement, then you can make a very complex statement slightly less complex by using the UNION ALL operator.
Optimization (determining the execution plan) takes place before the database knows what values will be substituted into the query. An execution plan cannot, therefore, depend on what those values are. For example:
SELECT info FROM tables WHERE ... AND somecolumn BETWEEN DECODE(:loval, 'ALL', somecolumn, :loval) AND DECODE(:hival, 'ALL', somecolumn, :hival);
Written as shown, the database cannot use an index on the somecolumn column, because the expression involving that column uses the same column on both sides of the BETWEEN.
This is not a problem if there is some other highly selective, indexable condition you can use to access the driving table. Often, however, this is not the case. Frequently, you might want to use an index on a condition like that shown but need to know the values of :loval, and so on, in advance. With this information, you can rule out the ALL case, which should not use the index.
If you want to use the index whenever real values are given for :loval and :hival (if you expect narrow ranges, even ranges where :loval often equals :hival), then you can rewrite the example in the following logically equivalent form:
SELECT /* change this half of UNION ALL if other half changes */ info FROM tables WHERE ... AND somecolumn BETWEEN :loval AND :hival AND (:hival != 'ALL' AND :loval != 'ALL')UNION ALL SELECT /* Change this half of UNION ALL if other half changes. */ info FROM tables WHERE ...
AND (:hival = 'ALL' OR :loval = 'ALL');
If you run EXPLAIN PLAN on the new query, then you seem to get both a desirable and an undesirable execution plan. However, the first condition the database evaluates for either half of the UNION ALL is the combined condition on whether :hival and :loval are ALL. The database evaluates this condition before actually getting any rows from the execution plan for that part of the query.
When the condition comes back false for one part of the UNION ALL query, that part is not evaluated further. Only the part of the execution plan that is optimum for the values provided is actually carried out. Because the final conditions on :hival and :loval are guaranteed to be mutually exclusive, only one half of the UNION ALL actually returns rows. (The ALL in UNION ALL is logically valid because of this exclusivity. It allows the plan to be carried out without an expensive sort to rule out duplicate rows for the two halves of the query.)
In certain circumstances, it is better to use IN rather than EXISTS. In general, if the selective predicate is in the subquery, then use IN. If the selective predicate is in the parent query, then use EXISTS.
Sometimes, Oracle can rewrite a subquery when used with an IN clause to take advantage of selectivity specified in the subquery. This is most beneficial when the most selective filter appears in the subquery and there are indexes on the join columns. Conversely, using EXISTS is beneficial when the most selective filter is in the parent query. This allows the selective predicates in the parent query to be applied before filtering the rows against the EXISTS criteria.
Below are two examples that demonstrate the benefits of IN and EXISTS. Both examples use the same schema with the following characteristics:
employees.employee_id field.orders.customer_id field.employees.department_id field.employees table has 27,000 rows.orders table has 10,000 rows.OE and HR schemas, which own these segments, were both analyzed with COMPUTE.This example demonstrates how rewriting a query to use IN can improve performance. This query identifies all employees who have placed orders on behalf of customer 144.
The following SQL statement uses EXISTS:
SELECT /* EXISTS example */ e.employee_id , e.first_name , e.last_name , e.salary FROM employees e WHERE EXISTS (SELECT 1 FROM orders o /* Note 1 */ WHERE e.employee_id = o.sales_rep_id /* Note 2 */ AND o.customer_id = 144); /* Note 3 */
Below is the execution plan (from V$SQL_PLAN) for the preceding statement. The plan requires a full table scan of the employees table, returning many rows. Each of these rows is then filtered against the orders table (through an index).
ID OPERATION OPTIONS OBJECT_NAME OPT COST ---- -------------------- --------------- ---------------------- --- ---------- 0 SELECT STATEMENT CHO 1 FILTER 2 TABLE ACCESS FULL EMPLOYEES ANA 155 3 TABLE ACCESS BY INDEX ROWID ORDERS ANA 3 4 INDEX RANGE SCAN ORD_CUSTOMER_IX ANA 1
Rewriting the statement using IN results in significantly fewer resources used.
The SQL statement using IN:
SELECT /* IN example */ e.employee_id , e.first_name , e.last_name , e.salary FROM employees e WHERE e.employee_id IN (SELECT o.sales_rep_id /* Note 4 */ FROM orders o WHERE o.customer_id = 144); /* Note 3 */
Below is the execution plan (from V$SQL_PLAN) for the preceding statement. The optimizer rewrites the subquery into a view, which is then joined through a unique index to the employees table. This results in a significantly better plan, because the view (that is, subquery) has a selective predicate, thus returning only a few employee_ids. These few employee_ids are then used to access the employees table through the unique index.
ID OPERATION OPTIONS OBJECT_NAME OPT COST ---- -------------------- --------------- ---------------------- --- ---------- 0 SELECT STATEMENT CHO 1 NESTED LOOPS 5 2 VIEW 3 3 SORT UNIQUE 3 4 TABLE ACCESS FULL ORDERS ANA 1 5 TABLE ACCESS BY INDEX ROWID EMPLOYEES ANA 1 6 INDEX UNIQUE SCAN EMP_EMP_ID_PK ANA
This example demonstrates how rewriting a query to use EXISTS can improve performance. This query identifies all employees from department 80 who are sales reps who have placed orders.
The following SQL statement uses IN:
SELECT /* IN example */ e.employee_id , e.first_name , e.last_name , e.department_id , e.salary FROM employees e WHERE e.department_id = 80 /* Note 5 */ AND e.job_id = 'SA_REP' /* Note 6 */ AND e.employee_id IN (SELECT o.sales_rep_id FROM orders o); /* Note 4 */
Below is the execution plan (from V$SQL_PLAN) for the preceding statement. The SQL statement was rewritten by the optimizer to use a view on the orders table, which requires sorting the data to return all unique employee_ids existing in the orders table. Because there is no predicate, many employee_ids are returned. The large list of resulting employee_ids are then used to access the employees table through the unique index.
ID OPERATION OPTIONS OBJECT_NAME OPT COST ---- -------------------- --------------- ---------------------- --- ---------- 0 SELECT STATEMENT CHO 1 NESTED LOOPS 125 2 VIEW 116 3 SORT UNIQUE 116 4 TABLE ACCESS FULL ORDERS ANA 40 5 TABLE ACCESS BY INDEX ROWID EMPLOYEES ANA 1 6 INDEX UNIQUE SCAN EMP_EMP_ID_PK ANA
The following SQL statement uses EXISTS:
SELECT /* EXISTS example */ e.employee_id , e.first_name , e.last_name , e.salary FROM employees e WHERE e.department_id = 80 /* Note 5 */ AND e.job_id = 'SA_REP' /* Note 6 */ AND EXISTS (SELECT 1 /* Note 1 */ FROM orders o WHERE e.employee_id = o.sales_rep_id); /* Note 2 */
|
Note:
|
Below is the execution plan (from V$SQL_PLAN) for the preceding statement. The cost of the plan is reduced by rewriting the SQL statement to use an EXISTS. This plan is more effective, because two indexes are used to satisfy the predicates in the parent query, thus returning only a few employee_ids. The employee_ids are then used to access the orders table through an index.
ID OPERATION OPTIONS OBJECT_NAME OPT COST ---- -------------------- --------------- ---------------------- --- ---------- 0 SELECT STATEMENT CHO 1 FILTER 2 TABLE ACCESS BY INDEX ROWID EMPLOYEES ANA 98 3 AND-EQUAL 4 INDEX RANGE SCAN EMP_JOB_IX ANA 5 INDEX RANGE SCAN EMP_DEPARTMENT_IX ANA 6 INDEX RANGE SCAN ORD_SALES_REP_IX ANA 8
|
Note: An even more efficient approach is to have a concatenated index on |
You can influence the optimizer's choices by setting the optimizer approach and goal, and by gathering representative statistics for the CBO. Sometimes, the application designer, who has more information about a particular application's data than is available to the optimizer, can choose a more effective way to execute a SQL statement. You can use hints in SQL statements to specify how the statement should be executed.
Hints, such as /*+FULL */ control access paths. For example:
SELECT /*+ FULL(e) */ e.ename FROM emp e WHERE e.job = 'CLERK';
Join order can have a significant effect on performance. The main objective of SQL tuning is to avoid performing unnecessary work to access rows that do not affect the result. This leads to three general rules:
The following example shows how to tune join order effectively:
SELECT info FROM taba a, tabb b, tabc c WHERE a.acol BETWEEN 100 AND 200 AND b.bcol BETWEEN 10000 AND 20000 AND c.ccol BETWEEN 10000 AND 20000 AND a.key1 = b.key1 AND a.key2 = c.key2;
The first three conditions in the previous example are filter conditions applying to only a single table each. The last two conditions are join conditions.
Filter conditions dominate the choice of driving table and index. In general, the driving table is the one containing the filter condition that eliminates the highest percentage of the table. Thus, because the range of 100 to 200 is narrow compared with the range of acol, but the ranges of 10000 and 20000 are relatively large, taba is the driving table, all else being equal.
With nested loop joins, the joins all happen through the join indexes, the indexes on the primary or foreign keys used to connect that table to an earlier table in the join tree. Rarely do you use the indexes on the nonjoin conditions, except for the driving table. Thus, after taba is chosen as the driving table, use the indexes on b.key1 and c.key2 to drive into tabb and tabc, respectively.
The work of the following join can be reduced by first joining to the table with the best still-unused filter. Thus, if "bcol BETWEEN ..." is more restrictive (rejects a higher percentage of the rows seen) than "ccol BETWEEN ...", the last join can be made easier (with fewer rows) if tabb is joined before tabc.
ORDERED or STAR hint to force the join order.
Be careful when joining views, when performing outer joins to views, and when reusing an existing view for a new purpose.
Joins to complex views are not recommended, particularly joins from one complex view to another. Often this results in the entire view being instantiated, and then the query is run against the view data.
For example, the following statement creates a view that lists employees and departments:
CREATE OR REPLACE VIEW emp_dept AS SELECT d.department_id , d.department_name , d.location_id , e.employee_id , e.last_name , e.first_name , e.salary , e.job_id FROM departments d ,employees e WHERE e.department_id (+) = d.department_id /
The following query finds employees in a specified state:
SELECT v.last_name, v.first_name, l.state_province FROM locations l, emp_dept v WHERE l.state_province = 'California' AND v.location_id = l.location_id (+) /
In the following plan, note that the emp_dept view is instantiated:
Plan Table -------------------------------------------------------------------------------- | Operation | Name | Rows | Bytes| Cost | Pstart| Pstop | -------------------------------------------------------------------------------- | SELECT STATEMENT | | | | | | | | FILTER | | | | | | | | NESTED LOOPS OUTER | | | | | | | | VIEW |EMP_DEPT | | | | | | | NESTED LOOPS OUTER | | | | | | | | TABLE ACCESS FULL |DEPARTMEN | | | | | | | TABLE ACCESS BY INDEX|EMPLOYEES | | | | | | | INDEX RANGE SCAN |EMP_DEPAR | | | | | | | TABLE ACCESS BY INDEX R|LOCATIONS | | | | | | | INDEX UNIQUE SCAN |LOC_ID_PK | | | | | | --------------------------------------------------------------------------------
Beware of writing a view for one purpose and then using it for other purposes to which it might be ill-suited. Querying from a view requires all tables from the view to be accessed for the data to be returned. Before reusing a view, determine whether all tables in the view need to be accessed to return the data. If not, then do not use the view. Instead, use the base table(s), or if necessary, define a new view. The goal is to refer to the minimum number of tables and views necessary to return the required data.
Consider the following example:
SELECT dname FROM emp_dept WHERE deptno=10;
The entire view is first instantiated by performing a join of the emp and dept tables and then aggregating the data. However, you can obtain dname and deptno directly from the dept table. It is inefficient to obtain this information by querying the dx view (which was declared in the earlier example).
Subquery unnesting merges the body of the subquery into the body of the statement that contains it, allowing the optimizer to consider them together when evaluating access paths and joins.
| See Also:
Oracle9i Data Warehousing Guide for an explanation of the dangers with subquery unnesting |
In the case of an outer join to a multitable view, the CBO (in Release 8.1.6 and later) can drive from an outer join column, if an equality predicate is defined on it.
An outer join within a view is problematic because the performance implications of the outer join are not visible.
Intermediate, or staging, tables are quite common in relational database systems, because they temporarily store some intermediate results. In many applications they are useful, but Oracle requires additional resources to create them. Always consider whether the benefit they could bring is more than the cost to create them. Avoid staging tables when the information is not reused multiple times.
Some additional considerations:
| See Also:
Oracle9i Data Warehousing Guide for detailed information on using materialized views |
Often, there is a beneficial impact on performance by restructuring indexes. This can involve the following:
Do not use indexes as a panacea. Application developers sometimes think that performance will improve if they create more indexes. If a single programmer creates an appropriate index, then this might indeed improve the application's performance. However, if 50 programmers each create an index, then application performance will probably be hampered.
Using triggers consumes system resources. If you use too many triggers, then you can find that performance is adversely affected and you might need to modify or disable them.
After restructuring the indexes and the statement, you can consider restructuring the data.
GROUP BY in response-critical code.You can maintain the existing execution plan of SQL statements over time either using stored statistics or stored SQL execution plans. Storing optimizer statistics for tables will apply to all SQL statements that refer to those tables. Storing an execution plan (that is, plan stability) maintains the plan for a single SQL statement. If both statistics and a stored plan are available for a SQL statement, then the optimizer uses the stored plan.
Applications should try to access each row only once. This reduces network traffic and reduces database load. Consider doing the following:
Often, it is necessary to calculate different aggregates on various sets of tables. Usually, this is done with multiple scans on the table, but it is easy to calculate all the aggregates with one single scan. Eliminating n-1 scans can greatly improve performance.
Combining multiple scans into one scan can be done by moving the WHERE condition of each scan into a CASE statement, which filters the data for the aggregation. For each aggregation, there could be another column that retrieves the data.
The following example asks for the count of all employees who earn less then 2000, between 2000 and 4000, and more than 4000 each month. This can be done with three separate queries:
SELECT COUNT (*) FROM employees WHERE salary < 2000; SELECT COUNT (*) FROM employees WHERE salary BETWEEN 2000 AND 4000; SELECT COUNT (*) FROM employees WHERE salary>4000;
However, it is more efficient to run the entire query in a single statement. Each number is calculated as one column. The count uses a filter with the CASE statement to count only the rows where the condition is valid. For example:
SELECT COUNT (CASE WHEN salary < 2000 THEN 1 ELSE null END) count1, COUNT (CASE WHEN salary BETWEEN 2001 AND 4000 THEN 1 ELSE null END) count2, COUNT (CASE WHEN salary > 4000 THEN 1 ELSE null END) count3 FROM employees;
This is a very simple example. The ranges could be overlapping, the functions for the aggregates could be different, and so on.
When appropriate, use INSERT, UPDATE, or DELETE... RETURNING to select and modify data with a single call. This technique improves performance by reducing the number of calls to the database.
| See Also:
Oracle9i SQL Reference for syntax on the |
When possible, use array processing. This means that an array of bind variable values is passed to Oracle for repeated execution. This is appropriate for iterative processes in which multiple rows of a set are subject to the same operation.
For example:
BEGIN FOR pos_rec IN (SELECT * FROM order_positions WHERE order_id = :id) LOOP DELETE FROM order_positions WHERE order_id = pos_rec.order_id AND order_position = pos_rec.order_position; END LOOP; DELETE FROM orders WHERE order_id = :id; END;
Alternatively, you could define a cascading constraint on orders. In the previous example, one SELECT and n DELETEs are executed. When a user issues the DELETE on orders DELETE FROM orders WHERE order_id = :id, the database automatically deletes the positions with a single DELETE statement.
| See Also:
Oracle9i Database Administrator's Guide or Oracle9i Heterogeneous Connectivity Administrator's Guide for information on tuning distributed queries |
|
 Copyright © 2000, 2002 Oracle Corporation. All Rights Reserved. |
|

