Release 2 (9.2)
Part Number A96520-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Data Warehousing Guide Release 2 (9.2) Part Number A96520-01 |
|
This chapter helps you create and manage a data warehouse, and discusses:
Data transformations are often the most complex and, in terms of processing time, the most costly part of the ETL process. They can range from simple data conversions to extremely complex data scrubbing techniques. Many, if not all, data transformations can occur within an Oracle9i database, although transformations are often implemented outside of the database (for example, on flat files) as well.
This chapter introduces techniques for implementing scalable and efficient data transformations within Oracle9i. The examples in this chapter are relatively simple. Real-world data transformations are often considerably more complex. However, the transformation techniques introduced in this chapter meet the majority of real-world data transformation requirements, often with more scalability and less programming than alternative approaches.
This chapter does not seek to illustrate all of the typical transformations that would be encountered in a data warehouse, but to demonstrate the types of fundamental technology that can be applied to implement these transformations and to provide guidance in how to choose the best techniques.
From an architectural perspective, you can transform your data in two ways:
The data transformation logic for most data warehouses consists of multiple steps. For example, in transforming new records to be inserted into a sales table, there may be separate logical transformation steps to validate each dimension key.
Figure 13-1 offers a graphical way of looking at the transformation logic.
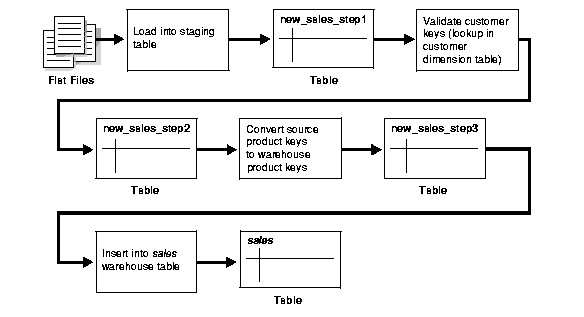
When using Oracle9i as a transformation engine, a common strategy is to implement each different transformation as a separate SQL operation and to create a separate, temporary staging table (such as the tables new_sales_step1 and new_sales_step2 in Figure 13-1) to store the incremental results for each step. This load-then-transform strategy also provides a natural checkpointing scheme to the entire transformation process, which enables to the process to be more easily monitored and restarted. However, a disadvantage to multistaging is that the space and time requirements increase.
It may also be possible to combine many simple logical transformations into a single SQL statement or single PL/SQL procedure. Doing so may provide better performance than performing each step independently, but it may also introduce difficulties in modifying, adding, or dropping individual transformations, as well as recovering from failed transformations.
With the introduction of Oracle9i, Oracle's database capabilities have been significantly enhanced to address specifically some of the tasks in ETL environments. The ETL process flow can be changed dramatically and the database becomes an integral part of the ETL solution.
The new functionality renders some of the former necessary process steps obsolete whilst some others can be remodeled to enhance the data flow and the data transformation to become more scalable and non-interruptive. The task shifts from serial transform-then-load process (with most of the tasks done outside the database) or load-then-transform process, to an enhanced transform-while-loading.
Oracle9i offers a wide variety of new capabilities to address all the issues and tasks relevant in an ETL scenario. It is important to understand that the database offers toolkit functionality rather than trying to address a one-size-fits-all solution. The underlying database has to enable the most appropriate ETL process flow for a specific customer need, and not dictate or constrain it from a technical perspective. Figure 13-2 illustrates the new functionality, which is discussed throughout later sections.
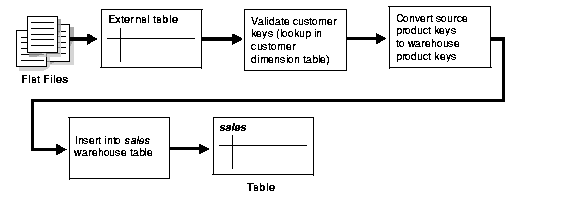
You can use the following mechanisms for loading a warehouse:
Before any data transformations can occur within the database, the raw data must become accessible for the database. One approach is to load it into the database. Chapter 12, "Transportation in Data Warehouses", discusses several techniques for transporting data to an Oracle data warehouse. Perhaps the most common technique for transporting data is by way of flat files.
SQL*Loader is used to move data from flat files into an Oracle data warehouse. During this data load, SQL*Loader can also be used to implement basic data transformations. When using direct-path SQL*Loader, basic data manipulation, such as datatype conversion and simple NULL handling, can be automatically resolved during the data load. Most data warehouses use direct-path loading for performance reasons.
Oracle's conventional-path loader provides broader capabilities for data transformation than a direct-path loader: SQL functions can be applied to any column as those values are being loaded. This provides a rich capability for transformations during the data load. However, the conventional-path loader is slower than direct-path loader. For these reasons, the conventional-path loader should be considered primarily for loading and transforming smaller amounts of data.
| See Also:
Oracle9i Database Utilities for more information on SQL*Loader |
The following is a simple example of a SQL*Loader controlfile to load data into the sales table of the sh sample schema from an external file sh_sales.dat. The external flat file sh_sales.dat consists of sales transaction data, aggregated on a daily level. Not all columns of this external file are loaded into sales. This external file will also be used as source for loading the second fact table of the sh sample schema, which is done using an external table:
The following shows the controlfile (sh_sales.ctl) to load the sales table:
LOAD DATA INFILE sh_sales.dat APPEND INTO TABLE sales FIELDS TERMINATED BY "|" ( PROD_ID, CUST_ID, TIME_ID, CHANNEL_ID, PROMO_ID, QUANTITY_SOLD, AMOUNT_SOLD)
It can be loaded with the following command:
$ sqlldr sh/sh control=sh_sales.ctl direct=true
Another approach for handling external data sources is using external tables. Oracle9i`s external table feature enables you to use external data as a virtual table that can be queried and joined directly and in parallel without requiring the external data to be first loaded in the database. You can then use SQL, PL/SQL, and Java to access the external data.
External tables enable the pipelining of the loading phase with the transformation phase. The transformation process can be merged with the loading process without any interruption of the data streaming. It is no longer necessary to stage the data inside the database for further processing inside the database, such as comparison or transformation. For example, the conversion functionality of a conventional load can be used for a direct-path INSERT AS SELECT statement in conjunction with the SELECT from an external table.
The main difference between external tables and regular tables is that externally organized tables are read-only. No DML operations (UPDATE/INSERT/DELETE) are possible and no indexes can be created on them.
Oracle9i's external tables are a complement to the existing SQL*Loader functionality, and are especially useful for environments where the complete external source has to be joined with existing database objects and transformed in a complex manner, or where the external data volume is large and used only once. SQL*Loader, on the other hand, might still be the better choice for loading of data where additional indexing of the staging table is necessary. This is true for operations where the data is used in independent complex transformations or the data is only partially used in further processing.
| See Also:
Oracle9i SQL Reference for a complete description of external table syntax and restrictions and Oracle9i Database Utilities for usage examples |
You can create an external table named sales_transactions_ext, representing the structure of the complete sales transaction data, represented in the external file sh_sales.dat. The product department is especially interested in a cost analysis on product and time. We thus create a fact table named cost in the sales history schema. The operational source data is the same as for the sales fact table. However, because we are not investigating every dimensional information that is provided, the data in the cost fact table has a coarser granularity than in the sales fact table, for example, all different distribution channels are aggregated.
We cannot load the data into the cost fact table without applying the previously mentioned aggregation of the detailed information, due to the suppression of some of the dimensions.
Oracle's external table framework offers a solution to solve this. Unlike SQL*Loader, where you would have to load the data before applying the aggregation, you can combine the loading and transformation within a single SQL DML statement, as shown in the following. You do not have to stage the data temporarily before inserting into the target table.
The Oracle object directories must already exist, and point to the directory containing the sh_sales.dat file as well as the directory containing the bad and log files.
CREATE TABLE sales_transactions_ext ( PROD_ID NUMBER(6), CUST_ID NUMBER, TIME_ID DATE, CHANNEL_ID CHAR(1), PROMO_ID NUMBER(6), QUANTITY_SOLD NUMBER(3), AMOUNT_SOLD NUMBER(10,2), UNIT_COST NUMBER(10,2), UNIT_PRICE NUMBER(10,2) ) ORGANIZATION external ( TYPE oracle_loader DEFAULT DIRECTORY data_file_dir ACCESS PARAMETERS ( RECORDS DELIMITED BY NEWLINE CHARACTERSET US7ASCII BADFILE log_file_dir:'sh_sales.bad_xt' LOGFILE log_file_dir:'sh_sales.log_xt' FIELDS TERMINATED BY "|" LDRTRIM ) location ( 'sh_sales.dat' ) )REJECT LIMIT UNLIMITED;
The external table can now be used from within the database, accessing some columns of the external data only, grouping the data, and inserting it into the costs fact table:
INSERT /*+ APPEND */ INTO COSTS ( TIME_ID, PROD_ID, UNIT_COST, UNIT_PRICE ) SELECT TIME_ID, PROD_ID, SUM(UNIT_COST), SUM(UNIT_PRICE) FROM sales_transactions_ext GROUP BY time_id, prod_id;
OCI and direct-path APIs are frequently used when the transformation and computation are done outside the database and there is no need for flat file staging.
Export and import are used when the data is inserted as is into the target system. No large volumes of data should be handled and no complex extractions are possible.
| See Also:
Chapter 11, "Extraction in Data Warehouses" for further information |
You have the following choices for transforming data inside the database:
Once data is loaded into an Oracle9i database, data transformations can be executed using SQL operations. There are four basic techniques for implementing SQL data transformations within Oracle9i:
The CREATE TABLE ... AS SELECT statement (CTAS) is a powerful tool for manipulating large sets of data. As shown in the following example, many data transformations can be expressed in standard SQL, and CTAS provides a mechanism for efficiently executing a SQL query and storing the results of that query in a new database table. The INSERT /*+APPEND*/ ... AS SELECT statement offers the same capabilities with existing database tables.
In a data warehouse environment, CTAS is typically run in parallel using NOLOGGING mode for best performance.
A simple and common type of data transformation is data substitution. In a data substitution transformation, some or all of the values of a single column are modified. For example, our sales table has a channel_id column. This column indicates whether a given sales transaction was made by a company's own sales force (a direct sale) or by a distributor (an indirect sale).
You may receive data from multiple source systems for your data warehouse. Suppose that one of those source systems processes only direct sales, and thus the source system does not know indirect sales channels. When the data warehouse initially receives sales data from this system, all sales records have a NULL value for the sales.channel_id field. These NULL values must be set to the proper key value. For example, You can do this efficiently using a SQL function as part of the insertion into the target sales table statement:
The structure of source table sales_activity_direct is as follows:
SQL> DESC sales_activity_direct Name Null? Type ------------ ----- ---------------- SALES_DATE DATE PRODUCT_ID NUMBER CUSTOMER_ID NUMBER PROMOTION_ID NUMBER AMOUNT NUMBER QUANTITY NUMBER INSERT /*+ APPEND NOLOGGING PARALLEL */ INTO sales SELECT product_id, customer_id, TRUNC(sales_date), 'S', promotion_id, quantity, amount FROM sales_activity_direct;
Another technique for implementing a data substitution is to use an UPDATE statement to modify the sales.channel_id column. An UPDATE will provide the correct result. However, if the data substitution transformations require that a very large percentage of the rows (or all of the rows) be modified, then, it may be more efficient to use a CTAS statement than an UPDATE.
Oracle's merge functionality extends SQL, by introducing the SQL keyword MERGE, in order to provide the ability to update or insert a row conditionally into a table or out of line single table views. Conditions are specified in the ON clause. This is, besides pure bulk loading, one of the most common operations in data warehouse synchronization.
Prior to Oracle9i, merges were expressed either as a sequence of DML statements or as PL/SQL loops operating on each row. Both of these approaches suffer from deficiencies in performance and usability. The new merge functionality overcomes these deficiencies with a new SQL statement. This syntax has been proposed as part of the upcoming SQL standard.
There are several benefits of the new MERGE statement as compared with the two other existing approaches.
The following discusses various implementations of a merge. The examples assume that new data for the dimension table products is propagated to the data warehouse and has to be either inserted or updated. The table products_delta has the same structure as products.
MERGE INTO products t USING products_delta s ON (t.prod_id=s.prod_id) WHEN MATCHED THEN UPDATE SET t.prod_list_price=s.prod_list_price, t.prod_min_price=s.prod_min_price WHEN NOT MATCHED THEN INSERT (prod_id, prod_name, prod_desc, prod_subcategory, prod_subcat_desc, prod_category, prod_cat_desc, prod_status, prod_list_price, prod_min_price) VALUES (s.prod_id, s.prod_name, s.prod_desc, s.prod_subcategory, s.prod_subcat_desc, s.prod_category, s.prod_cat_desc, s.prod_status, s.prod_list_price, s.prod_min_price);
A regular join between source products_delta and target products.
UPDATE products t SET (prod_name, prod_desc, prod_subcategory, prod_subcat_desc, prod_category, prod_cat_desc, prod_status, prod_list_price, prod_min_price) = (SELECT prod_name, prod_desc, prod_subcategory, prod_subcat_desc, prod_category, prod_cat_desc, prod_status, prod_list_price, prod_min_price from products_delta s WHERE s.prod_id=t.prod_id);
An antijoin between source products_delta and target products.
INSERT INTO products t SELECT * FROM products_delta s WHERE s.prod_id NOT IN (SELECT prod_id FROM products);
The advantage of this approach is its simplicity and lack of new language extensions. The disadvantage is its performance. It requires an extra scan and a join of both the products_delta and the products tables.
CREATE OR REPLACE PROCEDURE merge_proc IS CURSOR cur IS SELECT prod_id, prod_name, prod_desc, prod_subcategory, prod_subcat_desc, prod_category, prod_cat_desc, prod_status, prod_list_price, prod_min_price FROM products_delta; crec cur%rowtype; BEGIN OPEN cur; LOOP FETCH cur INTO crec; EXIT WHEN cur%notfound; UPDATE products SET prod_name = crec.prod_name, prod_desc = crec.prod_desc, prod_subcategory = crec.prod_subcategory, prod_subcat_desc = crec.prod_subcat_desc, prod_category = crec.prod_category, prod_cat_desc = crec.prod_cat_desc, prod_status = crec.prod_status, prod_list_price = crec.prod_list_price, prod_min_price = crec.prod_min_price WHERE crec.prod_id = prod_id; IF SQL%notfound THEN INSERT INTO products (prod_id, prod_name, prod_desc, prod_subcategory, prod_subcat_desc, prod_category, prod_cat_desc, prod_status, prod_list_price, prod_min_price) VALUES (crec.prod_id, crec.prod_name, crec.prod_desc, crec.prod_subcategory, crec.prod_subcat_desc, crec.prod_category, crec.prod_cat_desc, crec.prod_status, crec.prod_list_price, crec.prod_min_ price); END IF; END LOOP; CLOSE cur; END merge_proc; /
Many times, external data sources have to be segregated based on logical attributes for insertion into different target objects. It's also frequent in data warehouse environments to fan out the same source data into several target objects. Multitable inserts provide a new SQL statement for these kinds of transformations, where data can either end up in several or exactly one target, depending on the business transformation rules. This insertion can be done conditionally based on business rules or unconditionally.
It offers the benefits of the INSERT ... SELECT statement when multiple tables are involved as targets. In doing so, it avoids the drawbacks of the alternatives available to you using functionality prior to Oracle9i. You either had to deal with n independent INSERT ... SELECT statements, thus processing the same source data n times and increasing the transformation workload n times. Alternatively, you had to choose a procedural approach with a per-row determination how to handle the insertion. This solution lacked direct access to high-speed access paths available in SQL.
As with the existing INSERT ... SELECT statement, the new statement can be parallelized and used with the direct-load mechanism for faster performance.
The following statement aggregates the transactional sales information, stored in sales_activity_direct, on a per daily base and inserts into both the sales and the costs fact table for the current day.
INSERT ALL INTO sales VALUES (product_id, customer_id, today, 'S', promotion_id, quantity_per_day, amount_per_day) INTO costs VALUES (product_id, today, product_cost, product_price) SELECT TRUNC(s.sales_date) AS today, s.product_id, s.customer_id, s.promotion_id, SUM(s.amount_sold) AS amount_per_day, SUM(s.quantity) quantity_per_day, p.product_cost, p.product_price FROM sales_activity_direct s, product_information p WHERE s.product_id = p.product_id AND trunc(sales_date)=trunc(sysdate) GROUP BY trunc(sales_date), s.product_id, s.customer_id, s.promotion_id, p.product_cost, p.product_price;
The following statement inserts a row into the sales and cost tables for all sales transactions with a valid promotion and stores the information about multiple identical orders of a customer in a separate table cum_sales_activity. It is possible two rows will be inserted for some sales transactions, and none for others.
INSERT ALL WHEN promotion_id IN (SELECT promo_id FROM promotions) THEN INTO sales VALUES (product_id, customer_id, today, 'S', promotion_id, quantity_per_day, amount_per_day) INTO costs VALUES (product_id, today, product_cost, product_price) WHEN num_of_orders > 1 THEN INTO cum_sales_activity VALUES (today, product_id, customer_id, promotion_id, quantity_per_day, amount_per_day, num_of_orders) SELECT TRUNC(s.sales_date) AS today, s.product_id, s.customer_id, s.promotion_id, SUM(s.amount) AS amount_per_day, SUM(s.quantity) quantity_per_day, COUNT(*) num_of_orders, p.product_cost, p.product_price FROM sales_activity_direct s, product_information p WHERE s.product_id = p.product_id AND TRUNC(sales_date) = TRUNC(sysdate) GROUP BY TRUNC(sales_date), s.product_id, s.customer_id, s.promotion_id, p.product_cost, p.product_price;
The following statement inserts into an appropriate shipping manifest according to the total quantity and the weight of a product order. An exception is made for high value orders, which are also sent by express, unless their weight classification is not too high. It assumes the existence of appropriate tables large_freight_shipping, express_shipping, and default_shipping.
INSERT FIRST WHEN (sum_quantity_sold > 10 AND prod_weight_class < 5) OR (sum_quantity_sold > 5 AND prod_weight_class > 5) THEN INTO large_freight_shipping VALUES (time_id, cust_id, prod_id, prod_weight_class, sum_quantity_sold) WHEN sum_amount_sold > 1000 THEN INTO express_shipping VALUES (time_id, cust_id, prod_id, prod_weight_class, sum_amount_sold, sum_quantity_sold) ELSE INTO default_shipping VALUES (time_id, cust_id, prod_id, sum_quantity_sold) SELECT s.time_id, s.cust_id, s.prod_id, p.prod_weight_class, SUM(amount_sold) AS sum_amount_sold, SUM(quantity_sold) AS sum_quantity_sold FROM sales s, products p WHERE s.prod_id = p.prod_id AND s.time_id = TRUNC(sysdate) GROUP BY s.time_id, s.cust_id, s.prod_id, p.prod_weight_class;
The following example inserts new customers into the customers table and stores all new customers with cust_credit_limit higher then 4500 in an additional, separate table for further promotions.
INSERT FIRST WHEN cust_credit_limit >= 4500 THEN INTO customers INTO customers_special VALUES (cust_id, cust_credit_limit) ELSE INTO customers SELECT * FROM customers_new;
In a data warehouse environment, you can use procedural languages such as PL/SQL to implement complex transformations in the Oracle9i database. Whereas CTAS operates on entire tables and emphasizes parallelism, PL/SQL provides a row-based approached and can accommodate very sophisticated transformation rules. For example, a PL/SQL procedure could open multiple cursors and read data from multiple source tables, combine this data using complex business rules, and finally insert the transformed data into one or more target table. It would be difficult or impossible to express the same sequence of operations using standard SQL statements.
Using a procedural language, a specific transformation (or number of transformation steps) within a complex ETL processing can be encapsulated, reading data from an intermediate staging area and generating a new table object as output. A previously generated transformation input table and a subsequent transformation will consume the table generated by this specific transformation. Alternatively, these encapsulated transformation steps within the complete ETL process can be integrated seamlessly, thus streaming sets of rows between each other without the necessity of intermediate staging. You can use Oracle9i's table functions to implement such behavior.
Oracle9i's table functions provide the support for pipelined and parallel execution of transformations implemented in PL/SQL, C, or Java. Scenarios as mentioned earlier can be done without requiring the use of intermediate staging tables, which interrupt the data flow through various transformations steps.
A table function is defined as a function that can produce a set of rows as output. Additionally, table functions can take a set of rows as input. Prior to Oracle9i, PL/SQL functions:
Starting with Oracle9i, functions are not limited in these ways. Table functions extend database functionality by allowing:
Table functions can be defined in PL/SQL using a native PL/SQL interface, or in Java or C using the Oracle Data Cartridge Interface (ODCI).
| See Also:
PL/SQL User's Guide and Reference for further information and Oracle9i Data Cartridge Developer's Guide |
Figure 13-3 illustrates a typical aggregation where you input a set of rows and output a set of rows, in that case, after performing a SUM operation.
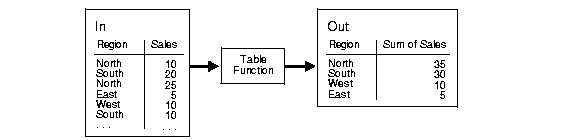
The pseudocode for this operation would be similar to:
INSERT INTO out SELECT * FROM ("Table Function"(SELECT * FROM in));
The table function takes the result of the SELECT on In as input and delivers a set of records in a different format as output for a direct insertion into Out.
Additionally, a table function can fan out data within the scope of an atomic transaction. This can be used for many occasions like an efficient logging mechanism or a fan out for other independent transformations. In such a scenario, a single staging table will be needed.
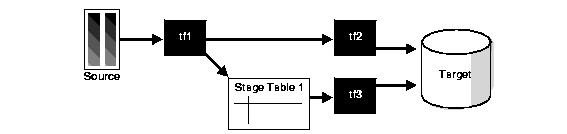
The pseudocode for this would be similar to:
INSERT INTO target SELECT * FROM (tf2(SELECT * FROM (tf1(SELECT * FROM source))));
This will insert into target and, as part of tf1, into Stage Table 1 within the scope of an atomic transaction.
INSERT INTO target SELECT * FROM tf3(SELECT * FROM stage_table1);
The following examples demonstrate the fundamentals of table functions, without the usage of complex business rules implemented inside those functions. They are chosen for demonstration purposes only, and are all implemented in PL/SQL.
Table functions return sets of records and can take cursors as input. Besides the Sales History schema, you have to set up the following database objects before using the examples:
REM object types CREATE TYPE product_t AS OBJECT ( prod_id NUMBER(6), prod_name VARCHAR2(50), prod_desc VARCHAR2(4000), prod_subcategory VARCHAR2(50), prod_subcat_desc VARCHAR2(2000). prod_category VARCHAR2(50), prod_cat_desc VARCHAR2(2000), prod_weight_class NUMBER(2), prod_unit_of_measure VARCHAR2(20), prod_pack_size VARCHAR2(30), supplier_id NUMBER(6), prod_status VARCHAR2(20), prod_list_price NUMBER(8,2), prod_min_price NUMBER(8,2) ); / CREATE TYPE product_t_table AS TABLE OF product_t; / COMMIT; REM package of all cursor types REM we have to handle the input cursor type and the output cursor collection REM type CREATE OR REPLACE PACKAGE cursor_PKG as TYPE product_t_rec IS RECORD ( prod_id NUMBER(6), prod_name VARCHAR2(50), prod_desc VARCHAR2(4000), prod_subcategory VARCHAR2(50), prod_subcat_desc VARCHAR2(2000), prod_category VARCHAR2(50), prod_cat_desc VARCHAR2(2000), prod_weight_class NUMBER(2), prod_unit_of_measure VARCHAR2(20), prod_pack_size VARCHAR2(30), supplier_id NUMBER(6), prod_status VARCHAR2(20), prod_list_price NUMBER(8,2), prod_min_price NUMBER(8,2)); TYPE product_t_rectab IS TABLE OF product_t_rec; TYPE strong_refcur_t IS REF CURSOR RETURN product_t_rec; TYPE refcur_t IS REF CURSOR; END; / REM artificial help table, used to demonstrate figure 13-4 CREATE TABLE obsolete_products_errors (prod_id NUMBER, msg VARCHAR2(2000));
The following example demonstrates a simple filtering; it shows all obsolete products except the prod_category Boys. The table function returns the result set as a set of records and uses a weakly typed ref cursor as input.
CREATE OR REPLACE FUNCTION obsolete_products(cur cursor_pkg.refcur_t) RETURN product_t_table IS prod_id NUMBER(6); prod_name VARCHAR2(50); prod_desc VARCHAR2(4000); prod_subcategory VARCHAR2(50); prod_subcat_desc VARCHAR2(2000); prod_category VARCHAR2(50); prod_cat_desc VARCHAR2(2000); prod_weight_class NUMBER(2); prod_unit_of_measure VARCHAR2(20); prod_pack_size VARCHAR2(30); supplier_id NUMBER(6); prod_status VARCHAR2(20); prod_list_price NUMBER(8,2); prod_min_price NUMBER(8,2); sales NUMBER:=0; objset product_t_table := product_t_table(); i NUMBER := 0; BEGIN LOOP -- Fetch from cursor variable FETCH cur INTO prod_id, prod_name, prod_desc, prod_subcategory, prod_subcat_desc, prod_category, prod_cat_desc, prod_weight_class, prod_unit_of_measure, prod_pack_size, supplier_id, prod_status, prod_list_price, prod_min_price; EXIT WHEN cur%NOTFOUND; -- exit when last row is fetched IF prod_status='obsolete' AND prod_category != 'Boys' THEN -- append to collection i:=i+1; objset.extend; objset(i):=product_t( prod_id, prod_name, prod_desc, prod_subcategory, prod_subcat_desc, prod_category, prod_cat_desc, prod_weight_class, prod_unit_ of_measure, prod_pack_size, supplier_id, prod_status, prod_list_price, prod_ min_price); END IF; END LOOP; CLOSE cur; RETURN objset; END; /
You can use the table function in a SQL statement to show the results. Here we use additional SQL functionality for the output.
SELECT DISTINCT UPPER(prod_category), prod_status FROM TABLE(obsolete_products(CURSOR(SELECT * FROM products))); UPPER(PROD_CATEGORY) PROD_STATUS -------------------- ----------- GIRLS obsolete MEN obsolete 2 rows selected.
The following example implements the same filtering than the first one. The main differences between those two are:
REM Same example, pipelined implementation REM strong ref cursor (input type is defined) REM a table without a strong typed input ref cursor cannot be parallelized REM CREATE OR REPLACE FUNCTION obsolete_products_pipe(cur cursor_pkg.strong_refcur_t) RETURN product_t_table PIPELINED PARALLEL_ENABLE (PARTITION cur BY ANY) IS prod_id NUMBER(6); prod_name VARCHAR2(50); prod_desc VARCHAR2(4000); prod_subcategory VARCHAR2(50); prod_subcat_desc VARCHAR2(2000); prod_category VARCHAR2(50); prod_cat_desc VARCHAR2(2000); prod_weight_class NUMBER(2); prod_unit_of_measure VARCHAR2(20); prod_pack_size VARCHAR2(30); supplier_id NUMBER(6); prod_status VARCHAR2(20); prod_list_price NUMBER(8,2); prod_min_price NUMBER(8,2); sales NUMBER:=0; BEGIN LOOP -- Fetch from cursor variable FETCH cur INTO prod_id, prod_name, prod_desc, prod_subcategory, prod_subcat_ desc, prod_category, prod_cat_desc, prod_weight_class, prod_unit_of_measure, prod_pack_size, supplier_id, prod_status, prod_list_price, prod_min_price; EXIT WHEN cur%NOTFOUND; -- exit when last row is fetched IF prod_status='obsolete' AND prod_category !='Boys' THEN PIPE ROW (product_t(prod_id, prod_name, prod_desc, prod_subcategory, prod_ subcat_desc, prod_category, prod_cat_desc, prod_weight_class, prod_unit_of_ measure, prod_pack_size, supplier_id, prod_status, prod_list_price, prod_min_ price)); END IF; END LOOP; CLOSE cur; RETURN; END; /
You can use the table function as follows:
SELECT DISTINCT prod_category, DECODE(prod_status, 'obsolete', 'NO LONGER REMOVE_AVAILABLE', 'N/A') FROM TABLE(obsolete_products_pipe(CURSOR(SELECT * FROM products))); PROD_CATEGORY DECODE(PROD_STATUS, ------------- ------------------- Girls NO LONGER AVAILABLE Men NO LONGER AVAILABLE 2 rows selected.
We now change the degree of parallelism for the input table products and issue the same statement again:
ALTER TABLE products PARALLEL 4;
The session statistics show that the statement has been parallelized:
SELECT * FROM V$PQ_SESSTAT WHERE statistic='Queries Parallelized'; STATISTIC LAST_QUERY SESSION_TOTAL -------------------- ---------- ------------- Queries Parallelized 1 3 1 row selected.
Table functions are also capable to fanout results into persistent table structures. This is demonstrated in the next example. The function filters returns all obsolete products except a those of a specific prod_category (default Men), which was set to status obsolete by error. The detected wrong prod_id's are stored in a separate table structure. Its result set consists of all other obsolete product categories. It furthermore demonstrates how normal variables can be used in conjunction with table functions:
CREATE OR REPLACE FUNCTION obsolete_products_dml(cur cursor_pkg.strong_refcur_t, prod_cat VARCHAR2 DEFAULT 'Men') RETURN product_t_table PIPELINED PARALLEL_ENABLE (PARTITION cur BY ANY) IS PRAGMA AUTONOMOUS_TRANSACTION; prod_id NUMBER(6); prod_name VARCHAR2(50); prod_desc VARCHAR2(4000); prod_subcategory VARCHAR2(50); prod_subcat_desc VARCHAR2(2000); prod_category VARCHAR2(50); prod_cat_desc VARCHAR2(2000); prod_weight_class NUMBER(2); prod_unit_of_measure VARCHAR2(20); prod_pack_size VARCHAR2(30); supplier_id NUMBER(6); prod_status VARCHAR2(20); prod_list_price NUMBER(8,2); prod_min_price NUMBER(8,2); sales NUMBER:=0; BEGIN LOOP -- Fetch from cursor variable FETCH cur INTO prod_id, prod_name, prod_desc, prod_subcategory, prod_subcat_ desc, prod_category, prod_cat_desc, prod_weight_class, prod_unit_of_measure, prod_pack_size, supplier_id, prod_status, prod_list_price, prod_min_price; EXIT WHEN cur%NOTFOUND; -- exit when last row is fetched IF prod_status='obsolete' THEN IF prod_category=prod_cat THEN INSERT INTO obsolete_products_errors VALUES (prod_id, 'correction: category '||UPPER(prod_cat)||' still available'); ELSE PIPE ROW (product_t( prod_id, prod_name, prod_desc, prod_subcategory, prod_ subcat_desc, prod_category, prod_cat_desc, prod_weight_class, prod_unit_of_ measure, prod_pack_size, supplier_id, prod_status, prod_list_price, prod_min_ price)); END IF; END IF; END LOOP; COMMIT; CLOSE cur; RETURN; END; /
The following query shows all obsolete product groups except the prod_category Men, which was wrongly set to status obsolete.
SELECT DISTINCT prod_category, prod_status FROM TABLE(obsolete_products_ dml(CURSOR(SELECT * FROM products))); PROD_CATEGORY PROD_STATUS ------------- ----------- Boys obsolete Girls obsolete 2 rows selected.
As you can see, there are some products of the prod_category Men that were obsoleted by accident:
SELECT DISTINCT msg FROM obsolete_products_errors; MSG ---------------------------------------- correction: category MEN still available 1 row selected.
Taking advantage of the second input variable changes the result set as follows:
SELECT DISTINCT prod_category, prod_status FROM TABLE(obsolete_products_ dml(CURSOR(SELECT * FROM products), 'Boys')); PROD_CATEGORY PROD_STATUS ------------- ----------- Girls obsolete Men obsolete 2 rows selected. SELECT DISTINCT msg FROM obsolete_products_errors; MSG ----------------------------------------- correction: category BOYS still available 1 row selected.
Because table functions can be used like a normal table, they can be nested, as shown in the following:
SELECT DISTINCT prod_category, prod_status FROM TABLE(obsolete_products_dml(CURSOR(SELECT * FROM TABLE(obsolete_products_pipe(CURSOR(SELECT * FROM products)))))); PROD_CATEGORY PROD_STATUS ------------- ----------- Girls obsolete 1 row selected.
Because the table function obsolete_products_pipe filters out all products of the prod_category Boys, our result does no longer include products of the prod_category Boys. The prod_category Men is still set to be obsolete by accident.
SELECT COUNT(*) FROM obsolete_products_errors; MSG ---------------------------------------- correction: category MEN still available
The biggest advantage of Oracle9i ETL is its toolkit functionality, where you can combine any of the latter discussed functionality to improve and speed up your ETL processing. For example, you can take an external table as input, join it with an existing table and use it as input for a parallelized table function to process complex business logic. This table function can be used as input source for a MERGE operation, thus streaming the new information for the data warehouse, provided in a flat file within one single statement through the complete ETL process.
The following sections offer examples of typical loading and transformation tasks:
This section presents a case study illustrating how to create, load, index, and analyze a large data warehouse fact table with partitions in a typical star schema. This example uses SQL*Loader to explicitly stripe data over 30 disks.
facts.facts table is partitioned by month into 12 partitions. To facilitate backup and recovery, each partition is stored in its own tablespace./dev/D1.1, /dev/D1.2, ... , /dev/D30.4./dev/D1.1 as its first datafile, the second tablespace has /dev/D4.2 as its first datafile, and so on, as illustrated in Figure 13-5.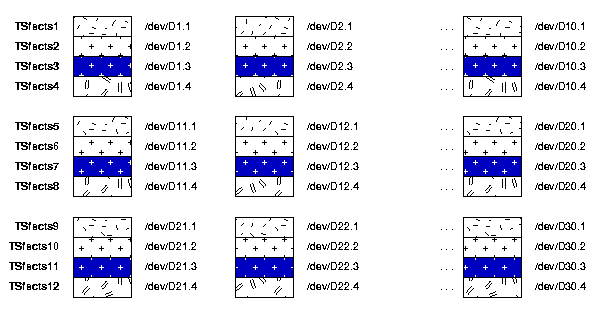
The following is the command to create a tablespace named Tsfacts1. Other tablespaces are created with analogous commands. On a 10-CPU machine, it should be possible to run all 12 CREATE TABLESPACE statements together. Alternatively, it might be better to run them in two batches of 6 (two from each of the three groups of disks).
CREATE TABLESPACE TSfacts1 DATAFILE /dev/D1.1' SIZE 1024MB REUSE, DATAFILE /dev/D2.1' SIZE 1024MB REUSE, DATAFILE /dev/D3.1' SIZE 1024MB REUSE, DATAFILE /dev/D4.1' SIZE 1024MB REUSE, DATAFILE /dev/D5.1' SIZE 1024MB REUSE, DATAFILE /dev/D6.1' SIZE 1024MB REUSE, DATAFILE /dev/D7.1' SIZE 1024MB REUSE, DATAFILE /dev/D8.1' SIZE 1024MB REUSE, DATAFILE /dev/D9.1' SIZE 1024MB REUSE, DATAFILE /dev/D10.1 SIZE 1024MB REUSE, DEFAULT STORAGE (INITIAL 100MB NEXT 100MB PCTINCREASE 0); ... CREATE TABLESPACE TSfacts2 DATAFILE /dev/D4.2' SIZE 1024MB REUSE, DATAFILE /dev/D5.2' SIZE 1024MB REUSE, DATAFILE /dev/D6.2' SIZE 1024MB REUSE, DATAFILE /dev/D7.2' SIZE 1024MB REUSE, DATAFILE /dev/D8.2' SIZE 1024MB REUSE, DATAFILE /dev/D9.2' SIZE 1024MB REUSE, DATAFILE /dev/D10.2 SIZE 1024MB REUSE, DATAFILE /dev/D1.2' SIZE 1024MB REUSE, DATAFILE /dev/D2.2' SIZE 1024MB REUSE, DATAFILE /dev/D3.2' SIZE 1024MB REUSE, DEFAULT STORAGE (INITIAL 100MB NEXT 100MB PCTINCREASE 0); ... CREATE TABLESPACE TSfacts4 DATAFILE /dev/D10.4' SIZE 1024MB REUSE, DATAFILE /dev/D1.4' SIZE 1024MB REUSE, DATAFILE /dev/D2.4' SIZE 1024MB REUSE, DATAFILE /dev/D3.4 SIZE 1024MB REUSE, DATAFILE /dev/D4.4' SIZE 1024MB REUSE, DATAFILE /dev/D5.4' SIZE 1024MB REUSE, DATAFILE /dev/D6.4' SIZE 1024MB REUSE, DATAFILE /dev/D7.4' SIZE 1024MB REUSE, DATAFILE /dev/D8.4' SIZE 1024MB REUSE, DATAFILE /dev/D9.4' SIZE 1024MB REUSE, DEFAULT STORAGE (INITIAL 100MB NEXT 100MB PCTINCREASE 0); ... CREATE TABLESPACE TSfacts12 DATAFILE /dev/D30.4' SIZE 1024MB REUSE, DATAFILE /dev/D21.4' SIZE 1024MB REUSE, DATAFILE /dev/D22.4' SIZE 1024MB REUSE, DATAFILE /dev/D23.4 SIZE 1024MB REUSE, DATAFILE /dev/D24.4' SIZE 1024MB REUSE, DATAFILE /dev/D25.4' SIZE 1024MB REUSE, DATAFILE /dev/D26.4' SIZE 1024MB REUSE, DATAFILE /dev/D27.4' SIZE 1024MB REUSE, DATAFILE /dev/D28.4' SIZE 1024MB REUSE, DATAFILE /dev/D29.4' SIZE 1024MB REUSE, DEFAULT STORAGE (INITIAL 100MB NEXT 100MB PCTINCREASE 0);
Extent sizes in the STORAGE clause should be multiples of the multiblock read size, where blocksize * MULTIBLOCK_READ_COUNT = multiblock read size.
INITIAL and NEXT should normally be set to the same value. In the case of parallel load, make the extent size large enough to keep the number of extents reasonable, and to avoid excessive overhead and serialization due to bottlenecks in the data dictionary. When PARALLEL=TRUE is used for parallel loader, the INITIAL extent is not used. In this case you can override the INITIAL extent size specified in the tablespace default storage clause with the value specified in the loader control file, for example, 64KB.
Tables or indexes can have an unlimited number of extents, provided you have set the COMPATIBLE initialization parameter to match the current release number, and use the MAXEXTENTS keyword on the CREATE or ALTER statement for the tablespace or object. In practice, however, a limit of 10,000 extents for each object is reasonable. A table or index has an unlimited number of extents, so set the PERCENT_INCREASE parameter to zero to have extents of equal size.
We create a partitioned table with 12 partitions, each in its own tablespace. The table contains multiple dimensions and multiple measures. The partitioning column is named dim_2 and is a date. There are other columns as well.
CREATE TABLE facts (dim_1 NUMBER, dim_2 DATE, ... meas_1 NUMBER, meas_2 NUMBER, ... ) PARALLEL PARTITION BY RANGE (dim_2) (PARTITION jan95 VALUES LESS THAN ('02-01-1995') TABLESPACE TSfacts1, PARTITION feb95 VALUES LESS THAN ('03-01-1995') TABLESPACE TSfacts2, ... PARTITION dec95 VALUES LESS THAN ('01-01-1996') TABLESPACE TSfacts12);
This section describes four alternative approaches to loading partitions in parallel. The different approaches to loading help you manage the ramifications of the PARALLEL=TRUE keyword of SQL*Loader that controls whether individual partitions are loaded in parallel. The PARALLEL keyword entails the following restrictions:
However, regardless of the setting of this keyword, if you have one loader process for each partition, you are still effectively loading into the table in parallel.
In this approach, assume 12 input files are partitioned in the same way as your table. You have one input file for each partition of the table to be loaded. You start 12 SQL*Loader sessions concurrently in parallel, entering statements like these:
SQLLDR DATA=jan95.dat DIRECT=TRUE CONTROL=jan95.ctl SQLLDR DATA=feb95.dat DIRECT=TRUE CONTROL=feb95.ctl . . . SQLLDR DATA=dec95.dat DIRECT=TRUE CONTROL=dec95.ctl
In the example, the keyword PARALLEL=TRUE is not set. A separate control file for each partition is necessary because the control file must specify the partition into which the loading should be done. It contains a statement such as the following:
LOAD INTO facts partition(jan95)
The advantage of this approach is that local indexes are maintained by SQL*Loader. You still get parallel loading, but on a partition level--without the restrictions of the PARALLEL keyword.
A disadvantage is that you must partition the input prior to loading manually.
In another common approach, assume an arbitrary number of input files that are not partitioned in the same way as the table. You can adopt a strategy of performing parallel load for each input file individually. Thus if there are seven input files, you can start seven SQL*Loader sessions, using statements like the following:
SQLLDR DATA=file1.dat DIRECT=TRUE PARALLEL=TRUE
Oracle partitions the input data so that it goes into the correct partitions. In this case all the loader sessions can share the same control file, so there is no need to mention it in the statement.
The keyword PARALLEL=TRUE must be used, because each of the seven loader sessions can write into every partition. In Case 1, every loader session would write into only one partition, because the data was partitioned prior to loading. Hence all the PARALLEL keyword restrictions are in effect.
In this case, Oracle attempts to spread the data evenly across all the files in each of the 12 tablespaces--however an even spread of data is not guaranteed. Moreover, there could be I/O contention during the load when the loader processes are attempting to write to the same device simultaneously.
In this example, you want precise control over the load. To achieve this, you must partition the input data in the same way as the datafiles are partitioned in Oracle.
This example uses 10 processes loading into 30 disks. To accomplish this, you must split the input into 120 files beforehand. The 10 processes will load the first partition in parallel on the first 10 disks, then the second partition in parallel on the second 10 disks, and so on through the 12th partition. You then run the following commands concurrently as background processes:
SQLLDR DATA=jan95.file1.dat DIRECT=TRUE PARALLEL=TRUE FILE=/dev/D1.1 ... SQLLDR DATA=jan95.file10.dat DIRECT=TRUE PARALLEL=TRUE FILE=/dev/D10.1 WAIT; ... SQLLDR DATA=dec95.file1.dat DIRECT=TRUE PARALLEL=TRUE FILE=/dev/D30.4 ... SQLLDR DATA=dec95.file10.dat DIRECT=TRUE PARALLEL=TRUE FILE=/dev/D29.4
For Oracle Real Application Clusters, divide the loader session evenly among the nodes. The datafile being read should always reside on the same node as the loader session.
The keyword PARALLEL=TRUE must be used, because multiple loader sessions can write into the same partition. Hence all the restrictions entailed by the PARALLEL keyword are in effect. An advantage of this approach, however, is that it guarantees that all of the data is precisely balanced, exactly reflecting your partitioning.
|
Note: Although this example shows parallel load used with partitioned tables, the two features can be used independent of one another. |
For this approach, all partitions must be in the same tablespace. You need to have the same number of input files as datafiles in the tablespace, but you do not need to partition the input the same way in which the table is partitioned.
For example, if all 30 devices were in the same tablespace, then you would arbitrarily partition your input data into 30 files, then start 30 SQL*Loader sessions in parallel. The statement starting up the first session would be similar to the following:
SQLLDR DATA=file1.dat DIRECT=TRUE PARALLEL=TRUE FILE=/dev/D1 . . . SQLLDR DATA=file30.dat DIRECT=TRUE PARALLEL=TRUE FILE=/dev/D30
The advantage of this approach is that as in Case 3, you have control over the exact placement of datafiles because you use the FILE keyword. However, you are not required to partition the input data by value because Oracle does that for you.
A disadvantage is that this approach requires all the partitions to be in the same tablespace. This minimizes availability.
This is probably the most basic use of external tables where the data volume is large and no transformations are applied to the external data. The load process is performed as follows:
PARALLEL CREATE TABLE AS SELECT or a PARALLEL INSERT statement.
CREATE TABLE products_ext (prod_id NUMBER, prod_name VARCHAR2(50), ..., price NUMBER(6.2), discount NUMBER(6.2)) ORGANIZATION EXTERNAL ( DEFAULT DIRECTORY (stage_dir) ACCESS PARAMETERS ( RECORDS FIXED 30 BADFILE 'bad/bad_products_ext' LOGFILE 'log/log_products_ext' ( prod_id POSITION (1:8) CHAR, prod_name POSITION (*,+50) CHAR, prod_desc POSITION (*,+200) CHAR, . . .) REMOVE_LOCATION ('new/new_prod1.txt','new/new_prod2.txt')) PARALLEL 5 REJECT LIMIT 200; # load it in the database using a parallel insert ALTER SESSION ENABLE PARALLEL DML; INSERT INTO TABLE products SELECT * FROM products_ext;
In this example, stage_dir is a directory where the external flat files reside.
Note that loading data in parallel can be performed in Oracle9i by using SQL*Loader. But external tables are probably easier to use and the parallel load is automatically coordinated. Unlike SQL*Loader, dynamic load balancing between parallel execution servers will be performed as well because there will be intra-file parallelism. The latter implies that the user will not have to manually split input files before starting the parallel load. This will be accomplished dynamically.
Another simple transformation is a key lookup. For example, suppose that sales transaction data has been loaded into a retail data warehouse. Although the data warehouse's sales table contains a product_id column, the sales transaction data extracted from the source system contains Uniform Price Codes (UPC) instead of product IDs. Therefore, it is necessary to transform the UPC codes into product IDs before the new sales transaction data can be inserted into the sales table.
In order to execute this transformation, a lookup table must relate the product_id values to the UPC codes. This table might be the product dimension table, or perhaps another table in the data warehouse that has been created specifically to support this transformation. For this example, we assume that there is a table named product, which has a product_id and an upc_code column.
This data substitution transformation can be implemented using the following CTAS statement:
CREATE TABLE temp_sales_step2 NOLOGGING PARALLEL AS SELECT sales_transaction_id, product.product_id sales_product_id, sales_customer_id, sales_time_id, sales_channel_id, sales_quantity_sold, sales_dollar_amount FROM temp_sales_step1, product WHERE temp_sales_step1.upc_code = product.upc_code;
This CTAS statement will convert each valid UPC code to a valid product_id value. If the ETL process has guaranteed that each UPC code is valid, then this statement alone may be sufficient to implement the entire transformation.
In the preceding example, if you must also handle new sales data that does not have valid UPC codes, you can use an additional CTAS statement to identify the invalid rows:
CREATE TABLE temp_sales_step1_invalid NOLOGGING PARALLEL AS SELECT * FROM temp_sales_step1 WHERE temp_sales_step1.upc_code NOT IN (SELECT upc_code FROM product);
This invalid data is now stored in a separate table, temp_sales_step1_invalid, and can be handled separately by the ETL process.
Another way to handle invalid data is to modify the original CTAS to use an outer join:
CREATE TABLE temp_sales_step2 NOLOGGING PARALLEL AS SELECT sales_transaction_id, product.product_id sales_product_id, sales_customer_id, sales_time_id, sales_channel_id, sales_quantity_sold, sales_dollar_amount FROM temp_sales_step1, product WHERE temp_sales_step1.upc_code = product.upc_code (+);
Using this outer join, the sales transactions that originally contained invalidated UPC codes will be assigned a product_id of NULL. These transactions can be handled later.
Additional approaches to handling invalid UPC codes exist. Some data warehouses may choose to insert null-valued product_id values into their sales table, while other data warehouses may not allow any new data from the entire batch to be inserted into the sales table until all invalid UPC codes have been addressed. The correct approach is determined by the business requirements of the data warehouse. Regardless of the specific requirements, exception handling can be addressed by the same basic SQL techniques as transformations.
A data warehouse can receive data from many different sources. Some of these source systems may not be relational databases and may store data in very different formats from the data warehouse. For example, suppose that you receive a set of sales records from a nonrelational database having the form:
product_id, customer_id, weekly_start_date, sales_sun, sales_mon, sales_tue, sales_wed, sales_thu, sales_fri, sales_sat
The input table looks like this:
SELECT * FROM sales_input_table;
PRODUCT_ID CUSTOMER_ID WEEKLY_ST SALES_SUN SALES_MON SALES_TUE SALES_WED SALES_THU SALES_FRI SALES_SAT ---------- ----------- --------- ---------- ---------- ---------- -------------------- ---------- ---------- 111 222 01-OCT-00 100 200 300 400 500 600 700 222 333 08-OCT-00 200 300 400 500 600 700 800 333 444 15-OCT-00 300 400 500 600 700 800 900
In your data warehouse, you would want to store the records in a more typical relational form in a fact table sales of the Sales History sample schema:
prod_id, cust_id, time_id, amount_sold
|
Note: A number of constraints on the |
Thus, you need to build a transformation such that each record in the input stream must be converted into seven records for the data warehouse's sales table. This operation is commonly referred to as pivoting, and Oracle offers several ways to do this.
The result of the previous example will resemble the following:
SELECT prod_id, cust_id, time_id, amount_sold FROM sales; PROD_ID CUST_ID TIME_ID AMOUNT_SOLD ---------- ---------- --------- ----------- 111 222 01-OCT-00 100 111 222 02-OCT-00 200 111 222 03-OCT-00 300 111 222 04-OCT-00 400 111 222 05-OCT-00 500 111 222 06-OCT-00 600 111 222 07-OCT-00 700 222 333 08-OCT-00 200 222 333 09-OCT-00 300 222 333 10-OCT-00 400 222 333 11-OCT-00 500 222 333 12-OCT-00 600 222 333 13-OCT-00 700 222 333 14-OCT-00 800 333 444 15-OCT-00 300 333 444 16-OCT-00 400 333 444 17-OCT-00 500 333 444 18-OCT-00 600 333 444 19-OCT-00 700 333 444 20-OCT-00 800 333 444 21-OCT-00 900
The pre-Oracle9i way of pivoting involved using CTAS (or parallel INSERT AS SELECT) or PL/SQL is shown in this section.
CREATE table temp_sales_step2 NOLOGGING PARALLEL AS SELECT product_id, customer_id, time_id, amount_sold FROM (SELECT product_id, customer_id, weekly_start_date, time_id, sales_sun amount_sold FROM sales_input_table UNION ALL SELECT product_id, customer_id, weekly_start_date+1, time_id, sales_mon amount_sold FROM sales_input_table UNION ALL SELECT product_id, cust_id, weekly_start_date+2, time_id, sales_tue amount_sold FROM sales_input_table UNION ALL SELECT product_id, customer_id, weekly_start_date+3, time_id, sales_web amount_sold FROM sales_input_table UNION ALL SELECT product_id, customer_id, weekly_start_date+4, time_id, sales_thu amount_sold FROM sales_input_table UNION ALL SELECT product_id, customer_id, weekly_start_date+5, time_id, sales_fri amount_sold FROM sales_input_table UNION ALL SELECT product_id, customer_id, weekly_start_date+6, time_id, sales_sat amount_sold FROM sales_input_table);
Like all CTAS operations, this operation can be fully parallelized. However, the CTAS approach also requires seven separate scans of the data, one for each day of the week. Even with parallelism, the CTAS approach can be time-consuming.
PL/SQL offers an alternative implementation. A basic PL/SQL function to implement a pivoting operation is shown in the following statement:
DECLARE CURSOR c1 is SELECT product_id, customer_id, weekly_start_date, sales_sun, sales_mon, sales_tue, sales_wed, sales_thu, sales_fri, sales_sat FROM sales_input_table; BEGIN FOR crec IN c1 LOOP INSERT INTO sales (prod_id, cust_id, time_id, amount_sold) VALUES (crec.product_id, crec.customer_id, crec.weekly_start_date, crec.sales_sun ); INSERT INTO sales (prod_id, cust_id, time_id, amount_sold) VALUES (crec.product_id, crec.customer_id, crec.weekly_start_date+1, crec.sales_mon ); INSERT INTO sales (prod_id, cust_id, time_id, amount_sold) VALUES (crec.product_id, crec.customer_id, crec.weekly_start_date+2, crec.sales_tue ); INSERT INTO sales (prod_id, cust_id, time_id, amount_sold) VALUES (crec.product_id, crec.customer_id, crec.weekly_start_date+3, crec.sales_wed ); INSERT INTO sales (prod_id, cust_id, time_id, amount_sold) VALUES (crec.product_id, crec.customer_id, crec.weekly_start_date+4, crec.sales_thu ); INSERT INTO sales (prod_id, cust_id, time_id, amount_sold) VALUES (crec.product_id, crec.customer_id, crec.weekly_start_date+5, crec.sales_fri ); INSERT INTO sales (prod_id, cust_id, time_id, amount_sold) VALUES (crec.product_id, crec.customer_id, crec.weekly_start_date+6, crec.sales_sat ); END LOOP; COMMIT; END;
This PL/SQL procedure can be modified to provide even better performance. Array inserts can accelerate the insertion phase of the procedure. Further performance can be gained by parallelizing this transformation operation, particularly if the temp_sales_step1 table is partitioned, using techniques similar to the parallelization of data unloading described in Chapter 11, "Extraction in Data Warehouses". The primary advantage of this PL/SQL procedure over a CTAS approach is that it requires only a single scan of the data.
Oracle9i offers a faster way of pivoting your data by using a multitable insert.
The following example uses the multitable insert syntax to insert into the demo table sh.sales some data from an input table with a different structure. The multitable insert statement looks like this:
INSERT ALL INTO sales (prod_id, cust_id, time_id, amount_sold) VALUES (product_id, customer_id, weekly_start_date, sales_sun) INTO sales (prod_id, cust_id, time_id, amount_sold) VALUES (product_id, customer_id, weekly_start_date+1, sales_mon) INTO sales (prod_id, cust_id, time_id, amount_sold) VALUES (product_id, customer_id, weekly_start_date+2, sales_tue) INTO sales (prod_id, cust_id, time_id, amount_sold) VALUES (product_id, customer_id, weekly_start_date+3, sales_wed) INTO sales (prod_id, cust_id, time_id, amount_sold) VALUES (product_id, customer_id, weekly_start_date+4, sales_thu) INTO sales (prod_id, cust_id, time_id, amount_sold) VALUES (product_id, customer_id, weekly_start_date+5, sales_fri) INTO sales (prod_id, cust_id, time_id, amount_sold) VALUES (product_id, customer_id, weekly_start_date+6, sales_sat) SELECT product_id, customer_id, weekly_start_date, sales_sun, sales_mon, sales_tue, sales_wed, sales_thu, sales_fri, sales_sat FROM sales_input_table;
This statement only scans the source table once and then inserts the appropriate data for each day.
|
 Copyright © 1996, 2002 Oracle Corporation. All Rights Reserved. |
|

