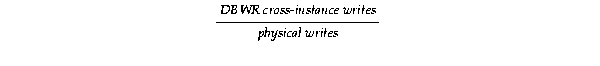Release 2 (9.2)
Part Number A96598-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Real Application Clusters Deployment and Performance Release 2 (9.2) Part Number A96598-01 |
|
This appendix explains how to configure locks to manage access to multiple blocks. Refer to this appendix only for a limited set of rare circumstances to override Oracle Real Application Clusters' default resource control scheme as performed by the Global Cache Service (GCS) and the Global Enqueue Service (GES). The topics in this appendix are:
The default scheme provides exceptional performance for all system types in all Real Application Clusters environments. In addition, assigning locks requires additional administrative effort. Therefore, using the default scheme is preferable to performing the tasks required to override the default strategy as described in this appendix.
|
Note: Only use the information in this appendix for exceptional cases. An example of this is an application where the data access patterns are almost exclusively read-mostly. |
Cache Fusion provides exceptional scalability and performance using cache-to-cache transfers of data that is not cached locally. In other words, before an instance reads a data block from disk, Oracle attempts to obtain the requested data from another instance's cache. If the requested block exists in another cache, then the data block is transferred across the interconnect from the holding instance to the requesting instance.
Real Application Clusters' resource control scheme guarantees the integrity of changes to data made by multiple instances. By default, each data block in an instance's buffer cache is protected by the Global Cache Service. The GCS tracks the access modes, roles, privileges, and states of these resources.
In rare situations, you may want to override the GCS, and the GES by configuring multi-block locks where one lock covers multiple data blocks in a file. If blocks are frequently accessed from the same instance, or if blocks are accessed from multiple nodes but in compatible modes such as shared mode for concurrent reads, then a lock configuration may improve performance.
To do this, set the GC_FILES_TO_LOCKS parameter and specify the number of locks that Oracle uses for particular files. The syntax of the parameter also enables you to specify lock allocations for groups of files as well as the number of contiguous data blocks to be covered by each lock. If you indiscriminately use values for GC_FILES_TO_LOCKS, then adverse performance such as excessive forced disk writes can result. Therefore, only set GC_FILES_TO_LOCKS for:
READ ONLY, and tablespaces containing rollback segments.
Using multiple locks for each file can be useful for the types of data shown in Table A-1.
| Situation | Reason |
|---|---|
|
When the composition of the data is mostly read-only. |
A few locks can cover many blocks without requiring frequent lock operations. These locks are released only when another instance needs to modify the data. Assigning locks can result in better performance on read-only data with parallel execution processing. If the data is strictly read-only, then consider designating the tablespace as read-only. |
|
When a large amount of data is modified by a relatively small set of instances. |
Lock assignments permit access to an un-cached database block to proceed without Parallel Cache Management activity. However, this is only possible if the block is already in the requesting instance's cache. |
Using locking can cause additional cross-instance cache management activity because conflicts can occur between instances that modify different database blocks. Resolution of false forced disk writes or excessive forced disk writes can require writing several blocks from the cache of the instance that currently owns access to the blocks.
Set the GC_FILES_TO_LOCKS initialization parameter to specify the number of locks covering data blocks in a datafile or set of datafiles. This section covers:
The syntax for the GC_FILES_TO_LOCKS parameter enables you to specify the relationship between locks and files. The syntax for this parameter and the meanings of the variables as shown in Table A-2 are:
GC_FILES_TO_LOCKS="{file_list=#locks[!blocks] [EACH][:]} . . ."
|
Note: All instance must have identical values for |
The default value for !blocks is 1. When you specify blocks, contiguous data blocks are covered by each of the #lock locks. To specify a value for blocks, use the exclamation point (!) separator. You would primarily specify blocks, and not specify the EACH keyword to allocate sets of locks to cover multiple datafiles.
Always set the !blocks value to avoid interfering with data partitioning if you have also used the optional free list groups. Normally you do not need to preallocate extents. When a row is inserted into a table and Oracle allocates new extents, Oracle allocates contiguous blocks that are specified with !blocks in GC_FILES_TO_LOCKS to the free list group associated with an instance.
For example, you can assign 300 locks to file 1 and 100 locks to file 2 by adding the following line to your initialization parameter file:
GC_FILES_TO_LOCKS = "1=300:2=100"
The following entry specifies a total of 1500 locks: 500 each for files 1, 2, and 3:
GC_FILES_TO_LOCKS = "1-3=500EACH"
By contrast, the following entry specifies a total of only 500 locks spread across the three files:
GC_FILES_TO_LOCKS = "1-3=500"
The following entry indicates that Oracle should use 1000 distinct locks to protect file 1. The data in the files is protected in groups of 25 contiguous locks.
GC_FILES_TO_LOCKS = "1=1000!25"
If you define a datafile with the AUTOEXTEND clause or if you issue the ALTER DATABASE ... DATAFILE ... RESIZE statement, then you may also need to adjust the lock assignment.
When you add new datafiles, decide whether these new files should be subject to the default control of the GCS or whether you want to assign locks using the GC_FILES_TO_LOCKS initialization parameter.
The following examples show different methods of mapping blocks to locks and how the same locks are used on multiple datafiles.
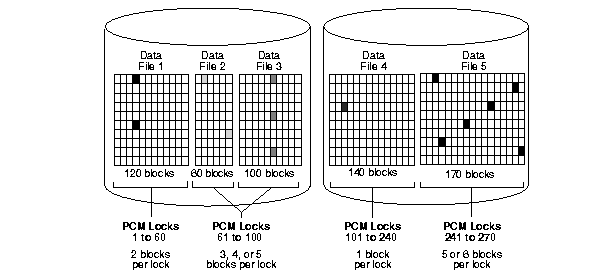
Figure A-1 shows an example of mapping blocks to locks for the parameter value GC_FILES_TO_LOCKS = "1=60:2-3=40:4=140:5=30".
In datafile 1 shown in Figure A-1, 60 locks map to 120 blocks, which is a multiple of 60. Each lock covers two data blocks.
In datafiles 2 and 3, 40 locks map to a total of 160 blocks. A lock can cover either one or two data blocks in datafile 2, and two or three data blocks in datafile 3. Thus, one lock can cover three, four, or five data blocks across both datafiles.
In datafile 4, each lock maps exactly to a single data block, since there is the same number of locks as data blocks.
In datafile 5, 30 locks map to 170 blocks, which is not a multiple of 30. Each lock therefore covers five or six data blocks.
Each lock illustrated in Figure A-1 can be held in either shared read mode or read-exclusive mode.
The following parameter setting allocates 500 locks to datafile 1; 400 locks each to files 2, 3, 4, 10, 11, and 12; 150 locks to file 5; 250 locks to file 6; and 300 locks collectively to files 7 through 9:
GC_FILES_TO_LOCKS = "1=500:2-4,10-12=400EACH:5=150:6=250:7-9=300"
This example assigns a total of (500 + (6*400) + 150 + 250 + 300) = 3600 locks. You can specify more than this number of locks if you add more datafiles.
In Example 2, 300 locks are allocated to datafiles 7, 8, and 9 collectively with the clause "7-9=300". The keyword EACH is omitted. If each of these datafiles contains 900 data blocks, then for a total of 2700 data blocks, then each lock covers nine data blocks. Because the datafiles are multiples of 300, the nine locks cover three data blocks in each datafile.
The following parameter value allocates 200 locks each to files 1 through 3; 50 locks to datafile 4; 100 locks collectively to datafiles 5, 6, 7, and 9; and 20 locks in contiguous 50-block groups to datafiles 8 and 10 combined:
GC_FILES_TO_LOCKS = "1-3=200EACH 4=50:5-7,9=100:8,10=20!50"
In this example, a lock assigned to the combined datafiles 5, 6, 7, and 9 covers one or more data blocks in each datafile, unless a datafile contains fewer than 100 data blocks. If datafiles 5 to 7 contain 500 data blocks each and datafile 9 contains 100 data blocks, then each lock covers 16 data blocks: one in datafile 9 and five each in the other datafiles. Alternatively, if datafile 9 contained 50 data blocks, half of the locks would cover 16 data blocks (one in datafile 9); the other half of the locks would only cover 15 data blocks (none in datafile 9).
The 20 locks assigned collectively to datafiles 8 and 10 cover contiguous groups of 50 data blocks. If the datafiles contain multiples of 50 data blocks and the total number of data blocks is not greater than 20 times 50, that is, 1000, then each lock covers data blocks in either datafile 8 or datafile 10, but not in both. This is because each of these locks covers 50 contiguous data blocks. If the size of datafile 8 is not a multiple of 50 data blocks, then one lock must cover data blocks in both files. If the sizes of datafiles 8 and 10 exceed 1000 data blocks, then some locks must cover more than one group of 50 data blocks, and the groups might be in different files.
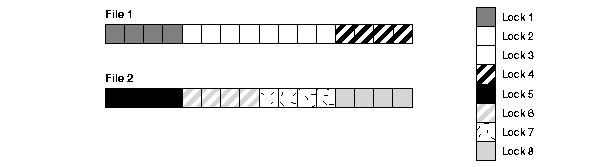
GC_FILES_TO_LOCKS="1-2=4"
In this example, four locks are specified for files 1 and 2. Therefore, the number of blocks covered by each lock is eight ((16+16)/4). The blocks are not contiguous.

GC_FILES_TO_LOCKS="1-2=4!8"
In this example, four locks are specified for files 1 and 2. However, the locks must cover eight contiguous blocks.

GC_FILES_TO_LOCKS="1-2=4!4EACH"
In this example, four locks are specified for file 1 and four for file 2. The locks must cover four contiguous blocks.
GC_FILES_TO_LOCKS="1=4:2=0"
In this example, file 1 has multi-block lock control with 4 locks. On file 2, locks are allocated.

Setting GC_FILES_TO_LOCKS in Real Application Clusters has further implications. For example, setting it can increase monitoring overhead and you may have to frequently adjust the parameter when the database grows or when you add files. Moreover, you cannot dynamically change the setting for GC_FILES_TO_LOCKS. To change the setting, you must stop the instances, alter the setting, and restart all the instances. In addition, consider the following topics in this section:
Sites that run continuously cannot afford to shut down for parameter value adjustments. Therefore, when you use the GC_FILES_TO_LOCKS parameter, remember to provide room for growth or room for files to extend.
You must also carefully consider how you use locks on files that do not grow significantly, such as read-only or read-mostly files. It is possible that better performance would result from assigning fewer locks for multiple blocks. However, if the expected CPU and memory savings due to fewer locks do not outweigh the administrative overhead, use the resource control scheme of the Global Cache and Global Enqueue Services.
Never include the following types of files in the GC_FILES_TO_LOCKS parameter list:
TEMPORARY tablespace.READ ONLY; the exception to this is a single lock that you can assign to ensure the tablespace does not have to contend for spare locks--but setting this lock is not mandatory--you can still leave this tablespace unassigned.To optimize parallel execution in Real Application Clusters environments when not using the default resource control scheme, you must accurately set the GC_FILES_TO_LOCKS parameter. Data block address locking in its default behavior assigns one lock to each block. For example, during a full table scan, a lock must be acquired for each block read into the scan. To accelerate full table scans, you use one of the following three possibilities:
The following guidelines affect memory usage, and thus indirectly affect performance:
If you set GC_FILES_TO_LOCKS, then Cache Fusion is disabled. In this case, you can use three statistics in the V$SYSSTAT view to measure the I/O performance related to global cache synchronization:
DBWR cross-instance writes occur when Oracle resolves inter-instance data block usage by writing the requested block to disk before the requesting node can use it.
Cache Fusion eliminates the disk I/O for current and consistent-read versions of blocks. This can lead to a substantial reduction in physical writes and reads performed by each instance.
You can obtain the following statistics to quantify the write I/Os required for global cache synchronization.
V$SYSSTAT view:
SELECT NAME, VALUE FROM V$SYSSTAT WHERE NAME IN ('DBWR cross-instance writes', 'remote instance undo block writes', 'remote instance undo header writes', 'physical writes');
Oracle responds with output similar to:
NAME VALUE --------------------------------------------------------- ---------- physical writes 41802 DBWR cross-instance writes 5403 remote instance undo block writes 0 remote instance undo header writes 2 4 rows selected.
Where the statistic physical writes refers to all physical writes that occurred from a particular instance performed by DBWR, the value for DBWR cross-instance writes accounts for all writes caused by writing a dirty buffer containing a data block that is requested for modification by another instance. Because the DBWR process also handles cross-instance writes, DBWR cross-instance writes are a subset of all physical writes.

Text description of the illustration sps81131.gif
The ratio shows how much disk I/O is related to writes to rollback segments.
V$LOCK_ACTIVITY and the physical reads statistics from V$SYSSTAT.
The following formula computes the percentage of reads that are only for local work where lock buffers for read represents the N-to-S block access mode conversions:
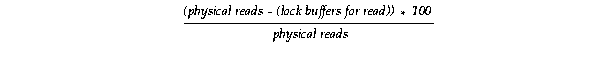
These so-called forced reads occur when a cached data block that was previously modified by the local instance had to be written to disk. This is due to a request from another instance, so the block is then re-acquired by the local instance for a read.
False forced writes occur when Oracle down-converts a lock that protects two or more blocks if the blocks are concurrently updated from different nodes. Assume that each node is updating a different block covered by the same lock. In this case, each node must write both blocks to disk even though the node is updating only one of them. This is necessary because the same lock covers both blocks.
Statistics are not available to show false forced write activity. To assess false forced write activity you can only consider circumstantial evidence as described in this section.
The following SQL statement shows the number of lock operations causing a write, and the number of blocks actually written:
SELECT VALUE/(A.COUNTER + B.COUNTER + C.COUNTER) "PING RATE" FROM V$SYSSTAT, V$LOCK_ACTIVITY A, V$LOCK_ACTIVITY B, V$LOCK_ACTIVITY C WHERE A.FROM_VAL = 'X' AND A.TO_VAL = 'NULL' AND B.FROM_VAL = 'X' AND B.TO_VAL = 'S' AND C.FROM_VAL = 'X' AND C.TO_VAL = 'SSX' AND NAME = 'DBWR cross-instance writes';
Table A-3 shows how to interpret the forced disk write rate.
Use this formula to calculate the percentage of false forced writes:
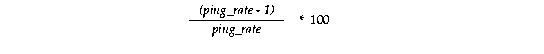
Then check the total number of writes and calculate the number due to false forced writes:
SELECT Y.VALUE "ALL WRITES", Z.VALUE "PING WRITES", Z.VALUE * pingrate "FALSE PINGS", FROM V$SYSSTAT Z, V$SYSSTAT Y, WHERE Z.NAME = 'DBWR cross-instance writes' AND Y.NAME = 'physical writes';
Here, ping_rate is given by the following SQL statement:
CREATE OR REPLACE VIEW PING_RATE AS SELECT ((VALUE/(A.COUNTER+B.COUNTER+C.COUNTER))-1)/ (VALUE/(A.COUNTER+B.COUNTER+C.COUNTER)) RATE FROM V$SYSSTAT, V$LOCK_ACTIVITY A, V$LOCK_ACTIVITY B, V$LOCK_ACTIVITY C WHERE A.FROM_VAL = 'X' AND A.TO_VAL = 'NULL' AND B.FROM_VAL = 'X' AND B.TO_VAL = 'S' AND C.FROM_VAL = 'X' AND C.TO_VAL = 'SSX' AND NAME = 'DBWR cross-instance writes';
The goal is not only to reduce overall forced disk writes, but also to reduce false forced writes. To do this, look at the distribution of instance locks in GC_FILES_TO_LOCKS and check the data in the files.
The following section describes the lock names and lock formats of locks. The topics in this section are:
Internally, Oracle global lock name formats use one of the following formats with parameter descriptions as shown in Table A-4:
type ID1 ID2type, ID1, ID2type (ID1, ID2)
For example, a space management lock might be named ST00. A lock might be named BL 1 900.
The clients of the lock manager define the lock type, for example BL for a lock, and two parameters, id1 and id2, and pass these parameters to the GCS API to open a lock. The lock manager does not distinguish between different types of locks. Each component of Oracle defines the type and the two parameters for its own needs, in other words, id1 and id2 have a meaning consistent with the requirements of each component.
All locks are Buffer Cache Management locks. Buffer Cache Management locks are of type BL. The syntax of lock names is type ID1 ID2, where:
type--Is always BL because locks are buffer locks.ID1--The database address of the blocks.ID2--The block class.
Examples of lock names are:
BL (100, 1)--This is a data block with lock element 100.BL (1000, 4)--This is a segment header block with lock element 1000.BL (27, 1)--This is an undo segment header with rollback segment Number 10. The formula for the rollback segment is 7 + (10 * 2).There are several different types and names of locks as shown in Table A-5:
|
 Copyright © 1999, 2002 Oracle Corporation. All Rights Reserved. |
|