| Oracle9i XML Database Developer's Guide - Oracle XML DB Release 2 (9.2) Part Number A96620-02 |
|





|
View PDF |
| Oracle9i XML Database Developer's Guide - Oracle XML DB Release 2 (9.2) Part Number A96620-02 |
|
|
View PDF |
This chapter explains the use of Oracle Text functionality in indexing and querying XML data. It contains the following sections:
This chapter describes the following aspects of Oracle Text:
XMLType dataOracle Text (aka interMedia Text) can be used to search XML documents. It extends Oracle9i by indexing any text or document stored in Oracle. It can also search documents in the file system and URLs.
Oracle Text enables the following:
You can query XML data stored in the database directly, without using Oracle Text. However, Oracle Text is useful for boosting query performance.
Oracle Text is a standard feature that comes with every Oracle9i Standard, Enterprise, and Personal edition license. It needs to be selected during installation. No special installation instructions are required.
Oracle Text is essentially a set of schema objects owned by CTXSYS. These objects are linked to the Oracle kernel. The schema objects are present when you perform an Oracle9i installation.
You can now perform Oracle Text searches on tables containing XMLType columns.
You can find more examples for Oracle Text and for creating section group indexes at the following site: http://otn.oracle.com/products/text
XML text is aVARCHAR2 or CLOB type in an Oracle9i database table with character semantics. Oracle Text can also deal with documents in a file system or in URLs, but we are not considering these document types in this chapter.
To simplify the examples included in this chapter they use a subset of the Oracle Text options and make the following assumptions:
CREATE INDEX or ALTER INDEX statement. Other parameter types available for CREATE INDEX and ALTER INDEX, are DATASTORE, FILTER, LEXER, STOPLIST, and WORDLIST.
Here is an example of using SECTION GROUP in CREATE INDEX:
CREATE INDEX my_index ON my_table ( my_column ) INDEXTYPE IS ctxsys.context PARAMETERS ( 'SECTION GROUP my_section_group' ) ;
AUTO_SECTION_GROUP and XML_SECTION_GROUP, and PATH_SECTION_GROUP.See Also:
|
With Oracle Text you can use the following users/roles:
CTXSYS to administer usersCTXAPP to create and delete Oracle Text preferences and use Oracle Text PL/SQL packagesUserCTXSYS is created at install time. Administer Oracle Text users as this user. User CTXSYS has the following privileges:
CTX_ADM PL/SQL package to start servers and set system-parametersCTXAPP roleAny user can create an Oracle Text index and issue a Text query. For additional tasks, use the CTXAPP role. This is a system-defined role that enables you to perform the following tasks:
CTX_DDL packageOracle Text's main purpose is to provide an implementation for the CONTAINS operator. The CONTAINS operator can be used in the WHERE clause of a SELECT statement to specify the query expression for a Text query.
Here is the CONTAINS syntax:
...WHERE CONTAINS([schema.]column,text_query VARCHAR2,[label NUMBER])
where:
For each row selected, CONTAINS returns a number between 0 and 100 that indicates how relevant the document row is to the query. The number 0 means that Oracle found no matches in the row. You can obtain this score with the SCORE operator.
The following example illustrates how the CONTAINS operator is used in a SELECT statement:
SELECT id FROM my_table WHERE CONTAINS (my_column, 'receipts') > 0
The'receipts' parameter of the CONTAINS operator is called the "Text Query Expression".
The following example searches for all documents in the text column that contain the word Oracle. The score for each row is selected with the SCORE operator using a label of 1:
SELECT SCORE(1), title from newsindex WHERE CONTAINS(text, 'oracle', 1) > 0 ORDER BY SCORE(1) DESC;
The CONTAINS operator must always be followed by the > 0 syntax. This specifies that the score value calculated by the CONTAINS operator must be greater than zero for the row selected.
When the SCORE operator is called, such as in a SELECT clause, the operator must reference the label value as shown in the example.
When documents have internal structure such as in HTML and XML, you can define document sections using embedded tags before you index. This enables you to query within the sections using the WITHIN operator.
You can query within attribute sections when you index with either XML_SECTION_GROUP, AUTO_SECTION_GROUP, or PATH_SECTION_GROUP your section group type. Consider the following XML document:
<book title="Tale of Two Cities">It was the best of times.</book>
If you use XML_SECTION_GROUP, you can specify any of the following sections:
This chapter only focuses on Zone, Field, and Attribute sections. For more information on Special sections see Oracle Text Reference and Oracle Text Application Developer's Guide.
The syntax for this is:
CTX_DDL.ADD_ZONE_SECTION( group_name in varchar2, section_name in varchar2, tag in varchar2);
To define a chapter as a Zone section, create an XML_SECTION_GROUP and define the Zone section as follows:
EXEC ctx_ddl_create_section_group('myxmlgroup', 'XML_SECTION_GROUP'); EXEC ctx_ddl.add_zone_section('myxmlgroup', 'chapter', 'chapter');
When you define Zone section as such and index the document set, you can query the XML chapter Zone section as follows:
'Cities within chapter'
The syntax for this is:
CTX_DDL.ADD_FIELD_SECTION( group_name in varchar2, section_name in varchar2, tag in varchar2);
To define a abstract as a Field section, create an XML_SECTION_GROUP and define the Field section as follows:
EXEC ctx_ddl_create_section_group('myxmlgroup', 'XML_SECTION_GROUP'); EXEC ctx_ddl.add_field_section('myxmlgroup', 'abstract', 'abstract');
When you define Field section as such and index the document set, you can query the XML abstract Field section as follows:
'Cities within abstract'
The syntax for this is:
CTX_DDL.ADD_ATTR_SECTION( group_name in varchar2, section_name in varchar2, tag in varchar2);
To define the booktitle attribute as an Attribute section, create an XML_SECTION_GROUP and define the Attribute section as follows:
EXEC ctx_ddl_create_section_group('myxmlgroup', 'XML_SECTION_GROUP'); EXEC ctx_ddl.add_attr_section('myxmlgroup', 'booktitle', 'book@title');
When you define the Attribute section as such and index the document set, you can query the XML booktitle attribute text as follows:
'Cities within booktitle'
The following constraints apply to querying within Attribute or Field sections:
WITHIN clause. Using the following XML document:
<book title="Tale of Two Cities">It was the best of times.</book>
querying on Tale will not work unless qualified with 'WITHIN title@book'.
WITHIN query.....Now is the time for all good <word type="noun"> men </word> to come to the aid......
The search would result in a regular query's, "good men", and ignore the intervening attribute text.
When you use the AUTO_SECTION_GROUP or PATH_SECTION_GROUP to index XML documents, Oracle9i automatically creates sections.
To search on Tale within the Attribute section booktitle, include the following WITHIN clause in your SELECT statement:
XML_SECTION_GROUP:
... WHERE CONTAINS ('Tale INPATH booktitle')>0;
PATH_SECTION_GROUP
... WHERE CONTAINS ('Tale INPATH title@book')>0;
The syntax for ALTER INDEX is:
ALTER INDEX [schema.]index REBUILD [ONLINE] [PARAMETERS (paramstring)];
where
paramstring = 'replace [datastore datastore_pref] [filter filter_pref] [lexer lexer_pref] [wordlist wordlist_pref] [storage storage_pref] [stoplist stoplist] [section group section_group] [memory memsize] | ... | add zone section section_name tag tag | add field section section_name tag tag [(VISIBLE | INVISIBLE)] | add attr section section_name tag tag@attr | add stop section tag'
The added section applies only to documents indexed after this operation. Thus for the change to take effect, you must manually re-index any existing documents that contain the tag. The index is not rebuilt by this statement.
Here is the WITHIN syntax for querying sections:
...WHERE CONTAINS(text,'XML WITHIN title') >0;...
This searches for expression text within a section. If you are using XML_SECTION_GROUP the following restrictions apply to the pre-defined zone, field, or attribute section:
WITHIN operators (nested WITHIN) whose section is a zone or special section.WITHIN operator.You can combine and nest WITHIN clauses. For finer grained searches of XML sections, you can use WITHIN clauses inside CONTAINS select statements.
The WITHIN operator has the following limitations:
WITHIN clause in a phrase. For example, you cannot write: term1 WITHIN section term2WITHIN with expansion operators, such as $ ! and *.WITHIN is a reserved word, you must escape the word with braces to search on it.
In Oracle9i Oracle Text introduced a new section type and new query operators which support an XPath-like query language. Indexes of type context with XML path searching are able to perform very complex section searches on XML documents. Here are the basic concepts of path indexing and path querying.
Section searching is enabled by defining section groups. To use XML path searching, the Oracle Text index must be created with the new section group, PATH_SECTION_GROUP as follows:
begin ctx_ddl.create_section_group('mypathgroup','PATH_SECTION_GROUP'); end;
To create the Oracle Text index use this command:
create index order_idx on library_catalog(text) indextype is ctxsys.context parameters ('SECTION GROUP mypathgroup');
The Oracle Text path query language is based on W3C XPath. For Oracle9i Release 1 (9.0.1) and higher, you can use the INPATH and HASPATH operators to express path queries.
You can use INPATH operator to perform path searching in XML documents. Table 7-2 summarizes the ways you can use the INPATH operator for path searching.
| Path Search Feature | Syntax | Description |
|---|---|---|
|
Simple Tag Searching |
virginia INPATH (//STATE) |
Finds all documents where the word "virginia" appears between <STATE> and </STATE>. The STATE element can appear at any level of the document structure. |
|
Case-sensitivity |
virginia INPATH (State) |
Tags and attribute names in path searching are case-sensitive. virginia |
|
Top-Level Tag Searching |
For example, the following query finds Quijote where it occurs between <order> and </order>: select id from library_catalog where contains(text,'Quijote INPATH(order)') > 0; Here <order> must be the top level tag. |
Finds all documents where "virginia" appears in a Legal element which is the top-level tag.'Legal' MUST be the top-level tag of the document.'virginia' may appear anywhere in this tag regardless of other intervening tags. For example: <?xml version="1.0" standalone="yes"?> <!-- <?xml-stylesheet type="text/xsl" href="./xsl/vacourtfiling(html).xsl"?> --> <Filing ID="f001" FilingType="Civil"> <AddressState>VIRGINIA</AddressState> </Address> ... </Legal> |
|
Any Level Tag Searching |
For example, a double slash indicates "any number of levels" down. The following query finds Quijote inside a <title> tag that occurs at the top level or any lower level: select id from library_catalog where contains(text,'Quijote INPATH(//title)') > 0; |
'Virginia' can appear anywhere within an 'Address' tag, which may appear within any other tags. for example: <?xml version="1.0" standalone="yes"?> <!-- <?xml-stylesheet type="text/xsl" href="./xsl/vacourtfiling(html).xsl"?> --> <Filing ID="f001" FilingType="Civil"> <AddressState> VIRGINIA </AddressState>... </Legal> |
|
Direct Parentage Path Searching |
virginia INPATH (//CourtInformation/Location) select id from library_catalog where contains(text,'virginia INPATH(order/item)') > 0; |
Finds all documents where "virginia" appears in a <?xml version="1.0" standalone="yes"?> <!-- <?xml-stylesheet type="text/xsl" href="./xsl/vacourtfiling(html).xsl"?> --> <Filing ID="f001" FilingType="Civil"> <AddressState> VIRGINIA </AddressState> </Address>... </CourtInformation> |
|
Single-Level Wildcard Searching |
'virginia INPATH (//CaseCaption/*/Location)' |
Finds all documents where "virginia" appears in a B element which is a grandchild of an A element. For instance, <A><D><B>virginia</B></D></A>. The intermediate element does not need to be an indexed XML tag. For example: <?xml version="1.0" standalone="yes"?> <!-- <?xml-stylesheet type="text/xsl" href="./xsl/vacourtfiling(html).xsl"?> --> <Filing ID="f001" FilingType="Civil"> <AddressState>VIRGINIA</AddressState>... </Legal> |
|
Multi-level Wildcard Searching |
'virginia INPATH (Legal/*/Filing/*/*/CourtInformation)' |
'Legal' must be a top-level tag, and there must be exactly one tag-level between 'Legal' and 'Filing', and two between 'Filing' and 'CourtInformation'. 'Virginia' may then appear anywhere within 'CourtInformation'. For example: <?xml version="1.0" standalone="yes"?> <!-- <?xml-stylesheet type="text/xsl" href="./xsl/vacourtfiling(html).xsl"?> --> <Filing ID="f001" FilingType="Civil"> <AddressState>VIRGINIA</AddressState> IN THE CIRCUIT COURT OF LOUDOUN COUNTY </CourtInformation>.... |
|
Descendant Searching |
virginia INPATH(A//B) |
Finds all documents where "virginia" appears in a B element which is some descendant (any level) of an A element. |
|
Attribute Searching |
virginia INPATH(A/@B) |
Finds all documents where "virginia" appears in the B attribute of an A element. You can search within an attribute value using the syntax <tag>/@<attribute>: select id from library_catalog where contains(text,'dvd You can use boolean AND and OR to combine existence or equality predicates in a test. select id from library_catalog where contains(text,'Levy or Cervantes |
|
Descendant/Attribute Existence Testing |
You can search for documents using the any-level tag searching: select id from library_catalog where contains (text,'Quijote INPATH(/order/title)') > 0; You can also use the "*" as a single level wildcard. The * matches exactly one level.: select id from library_catalog where contains (text,'Cervantes INPATH(/order/*/author)') > 0; |
Finds all documents where "virginia" appears in an A element which has a B element as a direct child. |
|
virginia INPATH (A[@B = "pot of gold"]), would, with the default lexer and stoplist, match any of the following: <A B="POT OF GOLD">virginia</A> By default, lexing is case-independent, so "pot" matches "POT", <A B="POT BLACK GOLD">virginia</A> By default, "of" is a stopword, and, in a query, would match any word in that position, <A B=" Pot OF Gold ">virginia</A> |
Finds all documents where "virginia" appears in an A element which has a B attribute whose value is "foo".
Within equality (See "Using INPATH Operator for Path Searching in XML Documents" ) is used to evaluate the test. Whitespace is mainly ignored in text indexing. Again, lexing is case-independent: <A B="pot_of_gold">virginia</A> Underscore is a non-alphabetic character, and is not a join character by default. As a result, it is treated more or less as whitespace and breaks up that string into three words. select id from library_catalog where contains(text,'(Bob the Builder) The following will not return rows: select id from library_catalog where contains(text,'(Bob the Builder) |
|
|
Numeric literals are allowed. But they are treated as text. The within equality is used to evaluate. This means that the query does NOT match. That is, <A B="5.0">virginia</A> does not match A[@B=5] where "5.0", a decimal is not considered the same as 5, an integer. |
||
|
virginia INPATH (A[B AND @C = "foo"])... |
Predicates can be conjunctively combined. |
|
|
virginia INPATH (A[@B = "foo"]/C/D) virginia INPATH(A//B[@C]/D[E])... |
Use the HASPATH operator to find all XML documents that contain a specified section path. HASPATH is used when you want to test for path existence. It is also very useful for section equality testing. To find all XML documents where an order has an item within it:
select id from library_catalog where contains(text,'HASPATH(order/item)') > 0;
will return all documents where the top-level tag is a order element which has a item element as a direct child.
In Oracle9i, Oracle Text introduces a new section type and new query operators which support an XPath-like query language. Indexes of type context with XML path searching are able to perform very complex section searches on XML documents. Here are more examples of path querying using INPATH and HASPATH. Assuming the following XML document:
<?xml version="1.0"?> <order> <item type="book"> <title>Crypto</title> <author>Levi</author> </item> <item type="dvd"> <title> Bob the Builder</title> <author>Auerbach</author> </item> <item type="book"> <title>Don Quijote</title> <author>Cervantes</author> </item> </order>
In general, use INPATH and HASPATH operators only when your index has been created with PATH_SECTION_GROUP. Use of PATH_SECTION_GROUP enables path searching. Path searching extends the syntax of the WITHIN operator so that the section name operand (right-hand-side) is a path instead of a section name.
Only use the HASPATH operator when your index has been created with the PATH_SECTION_GROUP. The syntax for the HASPATH operator is:
HASPATH searches an XML document set and returns a score of 100 for all documents where path exists. Parent and child paths are separated with the / character, for example, A/B/C. For example, the query:
...WHERE CONTAINS (col,'HASPATH(A/B/C)')>0;
finds and returns a score of 100 for the document:
<A><B><C>Virginia</C></B></A>
without having to reference Virginia at all.
HASPATH clause searches an XML document set and returns a score of 100 for all documents that have element A with content value and only that value. HASPATH is used to test equality. This is the "Section Equality Testing" feature of the HASPATH operator. The query:
...WHERE CONTAINS virginia INPATH A
finds <A>virginia</A>, but it also finds <A>virginia state</A>. To limit the query to the term virginia and nothing else, you can use a section equality test with the HASPATH operator. For example:
... WHERE CONTAINS (col,'HASPATH(A="virginia")'
finds and returns a score of 100 only for the first document, and not the second.
You can do tag value equality test with HASPATH:
select id from library_catalog
where CONTAINS(text,'HASPATH (//author="Auerbach")') >0;
To build a Oracle Text query application carry out the following steps:
After creating and preparing your data, you are ready to perform the next step. See "Step 1. Create a Section Group Preference".
CONTAINS operator. Now you can finish building your query application. See "Building a Query Application with Oracle Text".First determine the role you need. See Oracle Text Reference and "Oracle Text Users and Roles" , and grant the appropriate privilege as follows:
CONNECT system/manager GRANT ctxapp to scott; CONNECT scott/tiger
The first thing you must do is create a preference. This section describes how to create section preferences using PATH_SECTION_GROUP, XML_SECTION_GROUP, and AUTO_SECTION_GROUP. Table 7-3 describes the groups and summarizes their features.
| Section Group | Description |
|---|---|
|
XML_SECTION_GROUP |
Use this group type for indexing XML documents and for defining sections in XML documents. |
|
AUTO_SECTION_GROUP |
Use this group type to automatically create a zone section for each start-tag/end-tag pair in an XML document. The section names derived from XML tags are case-sensitive as in XML. Attribute sections are created automatically for XML tags that have attributes. Attribute sections are named in the form attribute@tag. Stop sections, empty tags, processing instructions, and comments are not indexed. The following limitations apply to automatic section groups:
|
|
PATH_SECTION_GROUP |
Use this group type to index XML documents. Behaves like the How is PATH_SECTION_GROUP Similar to AUTO_SECTION_GROUP? Documents are assumed to be XML, Every tag and every attribute is indexed by default, Stop sections can be added to prevent certain tags from being indexed, Only stop sections can be added How Does PATH_SECTION_GROUP Differ From AUTO_SECTION_GROUP? Path Searching is allowed at query time (see "Case Study: Searching XML-Based Conference Proceedings" and "You can use INPATH operator to perform path searching in XML documents. Table 7-2 summarizes the ways you can use the INPATH operator for path searching." ) with the new |
|
Note: If you are using the |
How do you determine which section groups is best for your application? This depends on your application. Table 7-4 lists some general guidelines to help you decide which of the XML_, AUTO_, or PATH_ section groups to use when indexing your XML documents, and why.
The following command creates a section group called, xmlgroup, with the XML_SECTION_GROUP group type:
EXEC ctx_ddl.create_section_group('myxmlgroup', 'XML_SECTION_GROUP');
You can set up your indexing operation to automatically create sections from XML documents using the section group AUTO_SECTION_GROUP. Here, Oracle creates zone sections for XML tags. Attribute sections are created for those tags that have attributes, and these attribute sections are named in the form "tag@attribute."
The following command creates a section group called autogroup with the AUTO_SECTION_GROUP group type. This section group automatically creates sections from tags in XML documents.
EXEC ctx_ddl.create_section_group('autogroup', 'AUTO_SECTION_GROUP');
To enable path section searching, index your XML document with PATH_SECTION_GROUP. For example:
EXEC ctx_ddl.create_section_group('xmlpathgroup', 'PATH_SECTION_GROUP');
To set the preference's attributes for XML_SECTION_GROUP, use the following procedures:
To set the preference's attributes for AUTO_SECTION_GROUP and PATH_SECTION_GROUP, use the following procedures:
There are corresponding CTX_DDL.DROP sections and CTX_DDL.REMOVE section commands.
The syntax for CTX_DDL.add_zone_section follows:
CTX_DDL.Add_Zone_Section ( group_name => 'my_section_group' /* whatever you called it in the preceding section */ section_name => 'author' /* what you want to call this section */ tag => 'my_tag' /* what represents it in XML */ );
where 'my_tag' implies opening with <my_tag> and closing with </my_tag>.
add_zone_section guidelines are listed here:
The syntax for CTX_DDL.ADD_ATTR_SECTION follows:
CTX_DDL.Add_Attr_Section ( /* call this as many times as you need to describe the attribute sections */ group_name => 'my_section_group' /* whatever you called it in the preceding section */ section_name => 'author' /* what you want to call this section */ tag => 'my_tag' /* what represents it in XML */ );
where 'my_tag' implies opening with <my_tag> and closing with </my_tag>.
Add_Attr_Section guidelines are listed here:
ADD_ATTR_SECTION adds an attribute section to an XML section group. This procedure is useful for defining attributes in XML documents as sections. This enables searching XML attribute text with the WITHIN operator.
The section_name:
WITHIN queries on the attribute text.The tag specifies the name of the attribute in tag@attr format. This is case-sensitive.
The syntax for CTX_DDL.Add_Field_Section follows:
CTX_DDL.Add_Field_Section ( group_name => 'my_section_group' /* whatever you called it in the preceding section */ section_name => 'qq' /* what you want to call this section */ tag => 'my_tag' /* what represents it in XML */ ); visible => TRUE or FALSE );
Add_Field_Section guidelines are listed here:
VISIBLE is set to TRUE then the text within the Field section will be indexed as part of the enclosing document. For example:
<state> Virginia </state> CTX_DDL.Add_Field_Section (
group_name => 'my_section_group' section_name => 'state' tag => 'state' visible => TRUE or FALSE );
If visible is set to TRUE, then searching on Virginia without specifying the state Field section produces a hit.
If visible is set to FALSE, then searching on Virginia without specifying the state Field section does not produce a hit.
Attribute section differs from Field section in the following ways:
WHERE CONTAINS (..., '... jeeves',...)...
does NOT find the document. This is similar to when Field sections have visible set to FALSE. Unlike Field sections, however, Attribute section within searches can distinguish between occurrences. Consider the document:
<comment author="jeeves"> I really like Oracle Text </comment> <comment author="bertram"> Me too </comment>
the query:
WHERE CONTAINS (...,'(cryil and bertram) WITHIN author', ...)...
will NOT find the document, because "jeeves" and "bertram" do not occur within the SAME attribute text.
tag@attr to a single section name. Attribute sections do not support default values. Given the document:
<!DOCTYPE foo [ <!ELEMENT foo (bar)> <!ELEMENT bar (#PCDATA)>
<!ATTLIST bar rev CDATA "8i"> ]> <foo> <bar>whatever</bar> </foo>
and attribute section:
ctx_ddl.add_attr_section('mysg','barrev','bar@rev');
the query:
8i within barrev does not hit the document, although in XML semantics, the "bar" element has a default value for its "rev" attribute.
CtX_DDL.Add_Stop_Section ( group_name => 'my_section_group' /* whatever you called it in the preceding section */ section_name => 'qq' /* what you want to call this section */ );
Create an index depending on which section group you used to create a preference:
To index your XML document when you have used XML_SECTION_GROUP, you can use the following statement:
CREATE INDEX myindex ON docs(htmlfile) INDEXTYPE IS ctxsys.context parameters('section group xmlgroup');
The following statement creates the index, myindex, on a column containing XML files using the AUTO_SECTION_GROUP:
CREATE INDEX myindex ON xmldocs(xmlfile) INDEXTYPE IS ctxsys.context PARAMETERS ('section group autogroup');
To index your XML document when you have used PATH_SECTION_GROUP, you can use the following statement:
CREATE INDEX myindex ON xmldocs(xmlfile) INDEXTYPE IS ctxsys.context PARAMETERS ('section group xmlpathgroup');
| See Also:
Oracle Text Reference for detailed notes on |
EXEC ctx_ddl_create_section_group('myxmlgroup', 'XML_SECTION_GROUP'); /* ADDING A FIELD SECTION */ EXEC ctx_ddl.Add_Field_Section /* THIS IS KEY */ ( group_name =>'my_section_group', section_name =>'author',/* do this for EVERY tag used after "WITHIN" */ tag =>'author' ); EXEC ctx_ddl.Add_Field_Section /* THIS IS KEY */ ( group_name =>'my_section_group', section_name =>'document',/*do this for EVERY tag after "WITHIN" */ tag =>'document' ); ... / /* ADDING AN ATTRIBUTE SECTION */ EXEC ctx_ddl.add_attr_section('myxmlgroup', 'booktitle', 'book@title'); /* The more sections you add to your index, the longer your search will take.*/ /* Useful for defining attributes in XML documents as sections. This allows*/ /* you to search XML attribute text using the WITHIN operator.*/ /* The section name: /* ** Is used for WITHIN queries on the attribute text. ** Cannot contain the colon (:) or dot (.) characters. ** Must be unique within group_name. ** Is case-insensitive. ** Can be no more than 64 bytes. ** The tag specifies the name of the attribute in tag@attr format. This is case-sensitive. */ /* Names used as arguments of the keyword WITHIN can be different from the actual XML tag names. Many tags can be mapped to the same name at query time.*/ /* Call CTX_DDL.Add_Zone_Section for each tag in your XML document that you need to search on. */ EXEC ctx_ddl.add_zone_section('myxmlgroup', 'mybooksec', 'mydocname(book)'); CREATE INDEX my_index ON my_table ( my_column ) INDEXTYPE IS ctxsys.context PARAMETERS ( 'SECTION GROUP my_section_group' ); SELECT my_column FROM my_table WHERE CONTAINS(my_column, 'smith WITHIN author') > 0;
See the section, "Querying with the CONTAINS Operator" for information about how to use the CONTAINS operator in query statements.
You can query within attribute sections when you index with either XML_SECTION_GROUP or AUTO_SECTION_GROUP as your section group type.
Assume you have an XML document as follows:
<book title="Tale of Two Cities">It was the best of times.</book>
You can define the section title@book as the attribute section title. You can do so with the CTX_DLL.Add_Attr_Section procedure or dynamically after indexing with ALTER INDEX.
|
Note: When you use the |
If you use the XML_SECTION_GROUP, you can name attribute sections anything with CTX_DDL.ADD_ATTR_SECTION.
To search on Tale within the attribute section title, issue the following query:
WHERE CONTAINS (...,'Tale WITHIN title', ...)
When you define the TITLE attribute section as such and index the document set, you can query the XML attribute text as follows:
... WHERE CONTAINS (...,'Cities WITHIN booktitle', ....)...
When you define the AUTHOR attribute section as such and index the document set, you can query the XML attribute text as follows:
... WHERE 'England WITHIN authors'
This example does the following:
drop table res_xml; CREATE TABLE res_xml ( pk NUMBER PRIMARY KEY , text CLOB ) ; insert into res_xml values(111, 'ENTITY chap8 "Chapter 8, <q>Keeping it Tidy: the XML Rule Book </q>"> this is the document section'); commit; --- --- script to create index on res_xml --- --- cleanup, in case we have run this before DROP INDEX res_index ; EXEC CTX_DDL.DROP_SECTION_GROUP ( 'res_sections' ) ; --- create a section group BEGIN CTX_DDL.CREATE_SECTION_GROUP ( 'res_sections', 'XML_SECTION_GROUP' ) ; CTX_DDL.ADD_FIELD_SECTION ( 'res_sections', 'chap8', '<q>') ; END ; / begin ctx_ddl.create_preference ( preference_name => 'my_basic_lexer', object_name => 'basic_lexer' ); ctx_ddl.set_attribute ( preference_name => 'my_basic_lexer', attribute_name => 'index_text', attribute_value => 'true' ); ctx_ddl.set_attribute ( preference_name => 'my_basic_lexer', attribute_name => 'index_themes', attribute_value => 'false'); end; / CREATE INDEX res_index ON res_xml(text) INDEXTYPE IS ctxsys.context PARAMETERS ( 'lexer my_basic_lexer SECTION GROUP res_sections' ) ;
Test the preceding index with a test query, such as:
SELECT pk FROM res_xml WHERE CONTAINS( text, 'keeping WITHIN chap8' )>0 ;
drop table explain_ex; create table explain_ex ( id number primary key, text varchar(2000) ); insert into explain_ex ( id, text ) values ( 1, 'thinks thinking thought go going goes gone went' || chr(10) || 'oracle orackle oricle dog cat bird' || chr(10) || 'President Clinton' ); insert into explain_ex ( id, text ) values ( 2, 'Last summer I went to New England' || chr(10) || 'I hiked a lot.' || chr(10) || 'I camped a bit.' ); commit;
Set Define Off select text from explain_ex WHERE CONTAINS ( text, '( $( think & go ) , ?oracle ) & ( dog , ( cat & bird ) ) & about(mammal during Bill Clinton)' ) > 0; select text from explain_ex WHERE CONTAINS ( text, 'about ( camping and hiking in new england )' ) > 0;
ctx_ddl_create_section_group('auto', 'AUTO_SECTION_GROUP');CREATE INDEX myindex ON docs(xmlfile_column) INDEXTYPE IS ctxsys.context PARAMETERS ('filter ctxsys.null_filter SECTION GROUP auto'); SELECT xmlfile_column FROM docs WHERE CONTAINS (xmlfile_column, 'virginia WITHIN title')>0;
EXEC ctx_ddl.create_section_group('xmlpathgroup', 'PATH_SECTION_GROUP');CREATE INDEX myindex ON xmldocs(xmlfile_column) INDEXTYPE IS ctxsys.context PARAMETERS ('section group xmlpathgroup');
SELECT xmlfile_column FROM xmldocs ... WHERE CONTAINS (column, 'Tale WITHIN title@book')>0;
Consider an XML file that defines the BOOK tag with a TITLE attribute as follows:
<BOOK TITLE="Tale of Two Cities"> It was the best of times. </BOOK> <Author="Charles Dickens"> Born in England in the town, Stratford_Upon_Avon </Author>
Recall the CTX_DDL.ADD_ATTR_SECTION syntax is:
CTX_DDL.Add_Attr_Section ( group_name, section_name, tag );
To define the title attribute as an attribute section, create an XML_SECTION_GROUP and define the attribute section as follows:
ctx_ddl_create_section_group('myxmlgroup', 'XML_SECTION_GROUP'); ctx_ddl.add_attr_section('myxmlgroup', 'booktitle', 'book@title'); ctx_ddl.add_attr_section('myxmlgroup', 'authors', 'author'); end;
An Oracle Text query application enables viewing documents returned by a query. You typically select a document from the hit list and then your application presents the document in some form.
With Oracle Text, you can render a document in different ways. For example, with the query terms highlighted. Highlighted query terms can be either the words of a word query or the themes of an ABOUT query in English. This rendering uses the CTX_DOC.HIGHLIGHT or CTX_DOC.MARKUP procedures.
You can also obtain theme information from documents with the CTX_DOC.THEMES PL/SQL package. Besides these there are several other CTX_DOC procedures for presenting your query results.
INPATH does not support working with highlighting or themes.
| See Also:
Oracle Text Reference for more information on the |
The Oracle9i datatype for storing XML, XMLType, is a core database feature.
You can create an Oracle Text index on this type, but you need a few database privileges first:
GRANT QUERY REWRITE TO <user>
Without this privilege, the create index will fail with:
ORA-01031: insufficient privileges
<user> should be the user creating the index. The database schema that owns the index, if different, does not need the grant.
init.ora file:
query_rewrite_enabled=true query_rewrite_integrity=trusted
or turn it on for the session as follows:
ALTER SESSION SET query_rewrite_enabled=true; ALTER SESSION SET query_rewrite_integrity=trusted;
Without these, queries will fail with:
DRG-10599: column is not indexed
These privileges are needed because XMLType is really an object, and you access it through a function, hence an Oracle Text index on an XMLType column is actually a function-based index on the getclobval() method of the type. These are the standard grants you need to use function-based indexes, however, unlike function-based B-Tree indexes, you do not need to calculate statistics.
|
Note: Oracle9i SQL Reference under CREATE INDEX, states: To create a function-based index in your own schema on your own table, in addition to the prerequisites for creating a conventional index, you must have the QUERY REWRITE system privilege. To create the index in another schema or on another schema's table, you must have the GLOBAL QUERY REWRITE privilege. In both cases, the table owner must also have the EXECUTE object privilege on the function(s) used in the function-based index. In addition, in order for Oracle to use function-based indexes in queries, the QUERY_REWRITE_ENABLED parameter must be set to TRUE, and the QUERY_REWRITE_INTEGRITY parameter must be set to TRUSTED. |
When an XMLType column is detected, and no section group is specified in the parameters string, the default system examines the new system parameter DEFAULT_XML_SECTION, and uses the section group specified there. At install time this system parameter is set to CTXSYS.PATH_SECTION_GROUP, which is the default path sectioner.
The default filter system parameter for XMLType is DEFAULT_FILTER_TEXT, which means that the INSO filter is not engaged by default.
Other than the database privileges and the special default section group system parameter, indexes on XMLType columns work like any other Oracle Text index.
Here is a simple example:
connect ctxsys/ctxsys GRANT QUERY REWRITE TO xtest; connect xtest/xtest CREATE TABLE xtest(doc sys.xmltype); INSERT INTO xtest VALUES (sys.xmltype.createxml('<A>simple</A>')); CREATE INDEX xtestx ON xtest(doc) INDEXTYPE IS ctxsys.context; ALTER SESSION SET query_rewrite_enabled = true; ALTER SESSION SET query_rewrite_integrity = trusted; SELECT a.doc.getclobval() FROM xtest a WHERE CONTAINS (doc, 'simple INPATH(A)')>0;
UriType columns can be indexed natively in Oracle9i database using Oracle Text. No special datastore is needed.
For example:
CREATE TABLE table uri_tab ( url sys.httpuritype); INSERT INTO uri_tab VALUES (sys.httpuritype.createUri('http://www.oracle.com')); CREATE INDEX urlx ON uri_tab(url) INDEXTYPE IS ctxsys.context; SELECT url FROM uri_tab WHERE CONTAINS(url, 'Oracle')>0;
Table 7-5 lists system parameters used for default preference names for Oracle Text indexing, when the column type is UriType:
Oracle9i Release 1(9.0.1) introduced the Oracle Text PATH_SECTION_GROUP, INPATH(), and HASPATH() query operators. These allow you to do XPath-like text query searches on XML documents using the CONTAINS operator. CONTAINS, however, supports only a subset of XPath functionality. Also, there are important semantic differences between the CONTAINS operator and the existsNode() function.
The existsNode, extract() and extractValue() SQL functions (and the corresponding member functions of XMLType) provide full XPath support. This release of Oracle9i also introduces new extension functions to XPath to support full text searches.
|
Note: This release does not support theme querying for Oracle Text |
Table 7-6 lists and compares CONTAINS() and existsNode() features for searching XMLType data.
Though XPath specifies a set of builtin text functions such as substring() and CONTAINS(), these are considerably less powerful than Oracle's full text search capabilities. New XPath extension functions are defined by Oracle to enable a richer set of text search capabilities. These extension functions are defined within the Oracle XML DB namespace : http://xmlns.oracle.com/xdb.
They can be used within XPath queries appearing in the context of existsNode(), extract() and extractValue() functions operating on XMLType instances.
|
Note: Like other procedures in |
The following lists the ora:contains features:
ConText index for their evaluation.The following is the syntax for the ora:contains function:
number contains(string, string, string?, string?)
where:
string, the first argument is input text valuestring, the second argument is the text query stringstring?, the optional third argument is the policy namestring?, the optional fourth argument is the policy ownerThe contains extension function in the Oracle XML DB namespace, takes the input text value as the first argument and the text query string as the second argument. It returns the score value - a number between 0 and 100.
The optional third and fourth arguments can be used to specify the name and owner of the CTX policy which is to be used for processing the text query. If the third argument is not specified, it defaults to the CTX policy named DEFAULT_POLICY_ORACONTAINS owned by CTXSYS. If the fourth argument is not specified, the policy owner is assumed to be the current user.
Assume the table xmltab contains XML documents corresponding to books with embedded chapters, each chapter containing a title and a body.
<book> <chapter> <title>...</title> <body>...</body> </chapter> <chapter> <title>...</title> <body>...</body> </chapter> ... </book>
Find books containing a chapter whose body contains the specified text query string:
select * from xmltab x where existsNode(value(x), '/book/chapter[ora:contains(body,"dog OR cat")>0]', 'xmlns:ora="http://xmlns.oracle.com/xdb"') = 1;
Extract chapters whose body contains the specified text query string.
select extract(value(x), '/book/chapter[ora:contains(body,"dog OR cat")>0]', 'xmlns:ora="http://xmlns.oracle.com/xdb"') from xmltab x;
This section includes syntax and examples for creating, updating, and dropping a policy for ora:contains():
The following CTX_DDL procedures creates/updates/drops a policy used by ora:contains():
A policy is a set of preferences used for processing ora:contains().
Table 7-7 describes the CTX_DDL functions for creating, updating, and dropping policies for use in your XPath searches.
Create lexer preference named mylex:
begin ctx_ddl.create_preference('mylex', 'BASIC_LEXER'); ctx_ddl.set_attribute('mylex', 'printjoins', '_-'); ctx_ddl.set_attribute ( 'mylex', 'index_themes', 'NO'); ctx_ddl.set_attribute ( 'mylex', 'index_text', 'YES'); end;
Create a stoplist preference named mystop.
begin ctx_ddl.create_stoplist('mystop', 'BASIC_STOPLIST'); ctx_ddl.add_stopword('mystop', 'because'); ctx_ddl.add_stopword('mystop', 'nonetheless'); ctx_ddl.add_stopword('mystop', 'therefore'); end;
Create a wordlist preference named 'mywordlist'.
begin ctx_ddl.create_preference('mywordlist', 'BASIC_WORDLIST'); ctx_ddl.set_attribute('mywordlist','FUZZY_MATCH','ENGLISH'); ctx_ddl.set_attribute('mywordlist','FUZZY_SCORE','0'); ctx_ddl.set_attribute('mywordlist','FUZZY_NUMRESULTS','5000'); ctx_ddl.set_attribute('mywordlist','SUBSTRING_INDEX','TRUE'); ctx_ddl.set _attribute('mywordlist','STEMMER','ENGLISH'); end; exec ctx_ddl.create_policy('my_policy', NULL, NULL, 'mylex', 'mystop', 'mywordlist');
or
exec ctx_ddl.create_policy(policy_name => 'my_policy', lexer => 'mylex', stoplist => 'mystop', wordlist => 'mywordlist');
Then you can issue the following existsNode() query with your own defined policy:
select * from xmltab x where existsNode(value(x), '/book/chapter[ora:contains(body,"dog OR cat", "my_policy")>0]', 'xmlns:ora="http://xmlns.oracle.com/xdb"') = 1;
You can also update your policy by using the following:
exec ctx_ddl.update_policy(policy_name => 'my_policy', lexer => 'my_new_lex');
You can drop your policy by using:
exec ctx_ddl.drop_policy(policy_name => 'my_policy');
You can also issue the existsNode() query using another user's policy, in this case, using Scott's policy:
select * from xmltab x where existsNode(value(x), '/book/chapter[ora:contains(body,"dog OR cat", "Scotts_policy","Scott")>0]', 'xmlns:ora="http://xmlns.oracle.com/xdb"') = 1;
The existsNode() SQL function, unlike the CONTAINS operator, cannot use ConText indexes to speed up its evaluation. To improve the performance of XPath searches in existsNode(), this release introduces a new index type, CTXXPATH.
The CTXXPATH index is a new indextype provided by Oracle Text. It is designed to serve as a primary filter for existsNode() processing, that is, it produces a superset of the results that would be produced by the existNode() function.
The existing ConText index type already has some XPath searching capabilities, but the ConText index type has some limitations:
existsNode(),
PATH_SECTION_GROUP.USER_LEXER or MULTI_LEXER preference.This limits the linguistic searching capabilities that ConText index type provides.
ConText index is asynchronous and does not follow the same transactional semantics as existsNode().ConText index does not handle namespaces nor user-defined entities.With all these limitations in mind, CTXXPATH index type was designed specifically to serve the purpose of existsNode() primary filter processing. You can still create ConText indexes with whichever preferences you need on XMLType columns, and this will be used to speed up CONTAINS operators. At the same time, you can create a CTXXPATH index to speedup the processing of existsNode().
CTXXPATH index type has the following characteristics:
existsNode() processing. It acts as a primary filter for the existsNode() function. In other words, it provides a superset of the results that existsNode() would provideexistsNode() by also returning unindexed rows as part of its result set in order to guarantee its requirement of returning a superset of the valid results.You create CTXXPATH indexes the same way you create ConText indexes. The syntax is the same as that of ConText index:
CREATE INDEX [schema.]index ON [schema.]table(XMLType column) INDEXTYPE IS ctxsys.CTXXPATH [PARAMETERS(paramstring)];
where
paramstring = '[storage storage_pref] [memory memsize] [populate | nopopulate]'
For example:
CREATE INDEX xml_idx ON xml_tab(col_xml) indextype is ctxsys.CTXXPATH;
or
CREATE INDEX xml_idx ON xml_tab(col_xml) indextype is ctxsys.CTXXPATH PARAMETERS('storage my_storage memory 40M');
The index can only be used to speed up queries using existsNode():
SELECT xml_id FROM xml_tab x WHERE x.col_xml.existsnode('/book/chapter[@title="XML"]')>1;
| See Also:
Chapter 4, "Using XMLType" for more information on using |
The only preference allowed for CTXXPATH index type is the STORAGE preference. You create the STORAGE preference the same way you would for a ConText index type.
For example:
begin ctx_ddl.create_preference('mystore', 'BASIC_STORAGE'); ctx_ddl.set_attribute('mystore', 'I_TABLE_CLAUSE', 'tablespace foo storage (initial 1K)'); ctx_ddl.set_attribute('mystore', 'K_TABLE_CLAUSE', 'tablespace foo storage (initial 1K)'); ctx_ddl.set_attribute('mystore', 'R_TABLE_CLAUSE', 'tablespace foo storage (initial 1K)'); ctx_ddl.set_attribute('mystore', 'N_TABLE_CLAUSE', 'tablespace foo storage (initial 1K)'); ctx_ddl.set_attribute('mystore', 'I_INDEX_CLAUSE', 'tablespace foo storage (initial 1K)'); end;
To synchronize DMLs, you can use the SYNC_INDEX procedure provided in the CTX_DDL package.
For example:
exec ctx_ddl.sync_index('xml_idx');
To optimize the CTXXPATH index, you can use the OPTIMIZE_INDEX() procedure provided in the CTX_DDL package. For example:
exec ctx_ddl.optimize_index('xml_idx', 'FAST');
or
exec ctx_ddl.optmize_index('xml_idx', 'FULL');
It is not guaranteed that a CTXXPATH index will always be used to speed up existsNode() processing. The following is a list of reasons why Oracle Text index may not be used under existsNode():
CTXXPATH index as primary filter.CTXXPATH index. Here are a list of XPath constructs CTXXPATH index cannot handle:
For the Optimizer to better estimate the costs and selectivities for the existsNode() function, you must gather statistics on CTXXPATH index by using ANALYZE command or DBMS_STATS package. You can analyze the index and compute the statistics using the ANALYZE command as follows:
ANALYZE INDEX myPathIndex COMPUTE STATISTICS;
or you can simply analyze the whole table:
ANALYZE TABLE XMLTAB COMPUTE STATISTICS;
The following sections describe several Oracle Text advanced techniques for fine-tuning your XML data search.
Oracle Text provides the CTX_DOC.HIGHLIGHT() procedure to generate highlight offsets and lengths for a Text query on a document. These offsets and lengths are generated for the terms in the document that satisfy a word query, phrase query, or about query. In Oracle9i Release 2 (9.2.0.2), Oracle Text extends highlight support for INPATH and HASPATH operators.
For INPATH, CTX_DOC.HIGHTLIGHT() calculates the offset and length for the left hand child of the INPATH operator just as with the WITHIN operator. This only applies to cases where the path child points to an element. For example, if the Text query expression is:
'txt INPATH(/A/B)' or 'txt INPATH(/A/B[@attr="atxt" and .="Btxt"])'
then CTX_DOC.HIGHTLIGHT() generates offsets and lengths for all occurrences of 'txt' in the document satisfying the INPATH query.
If the path child points to an attribute, then nothing is highlighted. For example, if the Text query expression is:
'atxt INPATH(/A/B/@attr)'
then no highlight information is generated.
For HASPATH, if its path operand points to an element, CTX_DOC.HIGHTLIGHT() calculates the offset and length for the bodies of the element pointed to by the XPath expression. For example, if the Text query expression is:
'HASPATH(/A/B)' or 'HASPATH(/A/B[@att="atxt"])'
then offsets and lengths are calculated for the bodies of elements pointed to by /A/B.
If the path operand points to an attribute, such as, 'HASPATH(/A/B/@Battr)', then no highlight information is generated.
If the operand does WITHIN-EQUAL/SECTION-EQUAL testing, then CTX_DOC.HIGHTLIGHT() outputs offsets and lengths of the elements pointed to by the path child of '='. If the path child of '=' points to an attribute, then no highlight information is generated. For example, if the Text query expression is:
'HASPATH(/A/B = "ABtxt")' or 'HASPATH(/A/B[@att="atxt"]= "ABtxt")'
then offsets and lengths are generated for the bodies of elements pointed to by /A/B. On the other hand, if the Text query expression is:
'HASPATH(/A/B/@att = "atxt")'
then no highlight information is generated because the path child '/A/B/@att' points to an attribute, not an element.
In previous releases, XML_SECTION_GROUP was unable to distinguish between tags in different DTDs. For example, suppose you use the following DTD for storing contact information:
<!DOCTYPE contact> <contact> <address>506 Blue Pool Road</address> <email>dudeman@radical.com</email> </contact>
Appropriate sections might look like:
ctx_ddl.add_field_section('mysg','email', 'email'); ctx_ddl.add_field_section('mysg','address','address');
This is fine until you have a different kind of document in the same table:
<!DOCTYPE mail> <mail> <address>dudeman@radical.com</address> </mail>
Now your address section, originally intended for street addresses, starts picking up email addresses, because of tag collision.
Oracle8i release 8.1.5 and higher allow you to specify doctype limiters to distinguish between these tags across doctypes. Simply specify the doctype in parentheses before the tag as follows:
ctx_ddl.add_field_section('mysg','email','email'); ctx_ddl.add_field_section('mysg','address','(contact)address'); ctx_ddl.add_field_section('mysg','email','(mail)address');
Now when the XML section group sees an address tag, it will index it as the address section when the document type is contact, or as the email section when the document type is mail.
If you have both doctype-limited and unlimited tags in a section group:
ctx_ddl.add_field_section('mysg','sec1','(type1)tag1'); ctx_ddl.add_field_section('mysg','sec2','tag1');
Then the limited tag applies when in the doctype, and the unlimited tag applies in all other doctypes.
Querying is unaffected by this. The query is done on the section name, not the tag, so querying for an email address would be done like:
radical WITHIN email
which, since we have mapped two different kinds of tags to the same section name, finds documents independent of which tags are used to express the email address.
In Oracle8i Release 1(8.1.5) and higher, XML_SECTION_GROUP offers the ability to index and search within attribute values. Consider a document with the following lines:
<comment author="jeeves"> I really like Oracle Text </comment>
Now XML_SECTION_GROUP offers an attribute section. This allows the inclusion of attribute values to index. For example:
ctx_ddl.add_attr_section('mysg','author','comment@author');
The syntax is similar to other add_section calls. The first argument is the name of the section group, the second is the name of the section, and the third is the tag, in the form <tag_name>@<attribute_name>. This tells Oracle Text to index the contents of the author attribute of the comment tag as the section "author".
Query syntax is just like for any other section:
WHERE CONTAINS ( ... ,'jeeves WITHIN author...',...)...
and finds the document.
Attribute sections allow you to search the contents of attributes. They do not allow you to use attribute values to specify sections to search. For instance, given the document:
<comment author="jeeves"> I really like Oracle Text </comment>
You can find this document by asking:
jeeves within comment@author
which is equivalent to "find me all documents which have a comment element whose author attribute's value includes the word jeeves".
However, there you cannot currently request the following:
interMedia within comment where (@author = "jeeves")
in other words, "find me all documents where interMedia appears in a comment element whose author is jeeves". This feature -- attribute value sensitive section searching -- is planned for future versions of the product.
Because the section group is defined before creating the index, Oracle8i Release 1 (8.1.5) is limited in its ability to cope with changing structured document sets; if your documents start coming with new tags, or you start getting new doctypes, you have to re-create the index to start making use of those tags.
With Oracle8i Release 2 (8.1.6) and higher you can add new sections to an existing index without rebuilding the index, using alter index and the new add section parameters string syntax:
add zone section <section_name> tag <tag> add field section <section_name> tag <tag> [ visible | invisible ]
For instance, to add a new zone section named tsec using the tag title:
alter index <indexname> rebuild parameters ('add zone section tsec tag title')
To add a new field section named asec using the tag author:
alter index <indexname> rebuild parameters ('add field section asec tag author')
This field section would be invisible by default, just like when using ADD_FIELD_SECTION. To add it as visible field section:
alter index <indexname> rebuild parameters ('add field section asec tag author visible')
Dynamic add section only modifies the index metadata, and does not rebuild the index in any way. This means that these sections take effect for any document indexed after the operation, and do not affect any existing documents -- if the index already has documents with these sections, they must be manually marked for re-indexing (usually with an update of the indexed column to itself).
This operation does not support addition of special sections. Those would require all documents to be re-indexed, anyway. This operation cannot be done using rebuild online, but it should be a fairly quick operation.
The following constraints apply to querying within attribute sections:
<book title="Tale of Two Cities">It was the best of times.</book>
A query on Tale by itself does not produce a hit on the document unless qualified with WITHIN title@book. This behavior is like field sections when you set the visible flag set to false.
WITHIN query.Now is the time for all good <word type="noun"> men </word> to come to the aid.
Then this document would hit on the regular query good men, ignoring the intervening attribute text.
WITHIN queries can distinguish repeated attribute sections. This behavior is like zone sections but unlike field sections. For example, for the following document:
<book title="Tale of Two Cities">It was the best of times.</book> <book title="Of Human Bondage">The sky broke dull and gray.</book>
Assume the book is a zone section and book@author is an attribute section. Consider the query:
'(Tale and Bondage) WITHIN book@author'
This query does not hit the document, because tale and bondage are in different occurrences of the attribute section book@author.
Zone sections can repeat. Each occurrence is treated as a separate section. For example, if <H1> denotes a heading section, they can repeat in the same documents as follows:
<H1> The Brown Fox </H1> <H1> The Gray Wolf </H1>
Assuming that these zone sections are named Heading.
The query:
WHERE CONTAINS (..., 'Brown WITHIN Heading', ...)...
returns this document.
But the query:
WHERE CONTAINS (...,' (Brown and Gray) WITHIN Heading',...)...
does not.
Zone sections can overlap each other. For example, if <B> and <I> denote two different zone sections, they can overlap in document as follows:
plain <B> bold <I> bold and italic </B> only italic </I> plain
Zone sections can nest, including themselves as follows:
<TD> <TABLE> <TD>nested cell</TD> </TABLE> </TD>
Using the WITHIN operator, you can write queries to search for text in sections within sections.
For example, assume the BOOK1, BOOK2, and AUTHOR zone sections occur as follows in documents doc1 and doc2:
doc1:
<book1><author>Scott Tiger</author> This is a cool book to read.</book1>
doc2:
<book2> <author>Scott Tiger</author> This is a great book to read.</book2>
Consider the nested query:
'Scott WITHIN author WITHIN book1'
This query returns only doc1.
The CTX_OBJECT_ATTRIBUTES view displays attributes that can be assigned to preferences of each object. It can be queried by all users.
Check out the structure of CTX_OBJECTS and CTX_OBJECT_ATTRIBUTE view, with the following DESCRIBE commands. Because we are only interested in querying XML documents in this chapter, we focus on XML_SECTION_GROUP and AUTO_SECTION_GROUP.
Describe ctx_objects SELECT obj_class, obj_name FROM ctx_objects ORDRR BY obj_class, obj_name;
The result is:
... SECTION_GROUP AUTO_SECTION_GROUP <<== SECTION_GROUP BASIC_SECTION_GROUP SECTION_GROUP HTML_SECTION_GROUP SECTION_GROUP NEWS_SECTION_GROUP SECTION_GROUP NULL_SECTION_GROUP SECTION_GROUP XML_SECTION_GROUP <<== ... Describe ctx_object_attributes SELECT oat_attribute FROM ctx_object_attributes WHERE oat_object = 'XML_SECTION_GROUP';
The result is:
OAT_ATTRIBUTE ------------- ATTR FIELD SPECIAL ZONE SELECT oat_attribute FROM ctx_object_attributes WHERE oat_object = 'AUTO_SECTION_GROUP';
The result is:
OAT_ATTRIBUTE ------------- STOP
This case study uses INPATH, HASPATH, and extract() to search a XML-based conference proceedings.
|
Note: You can download this sample application from http://otn.oracle.com/products/text |
Documents are structured presentations of information. You can define a document as an asset that contains structure, content, and presentation. This case study describes how to search for content and structure at the same time. All features described here are available in Oracle9i Release 1 (9.0.1) and higher.
Consider an online conference proceedings search where the conference attendees can perform full text searches on the structure of the papers, for example search on title, author, abstract, and so on.
Follow these tasks to build this conference proceedings search case study:
You must be granted with QUERY REWRITE system privileges to create a Functional Index. You must also have the following initialization parameters defined to create a Functional Index:
For example, create a table, Proceedings with two columns: tk, the paper's id, and papers, the content. Store the paper's content as an XMLType.
CREATE TABLE Proceedings (tk number, papers XMLTYPE);
Now populate table Proceedings with some conference papers:
INSERT INTO Proceedings(tk,papers) VALUES (1, XMLType.createXML( '<?xml version="1.0"?> <paper> <title>Accelerating Dynamic Web Sites using Edge Side Includes</title> <authors>Soo Yun and Scott Davies</authors> <company> Oracle Corporation </company> <abstract> The main focus of this presentation is on Edge Side Includes (ESI). ESI is a simple markup language which is used to mark cacheable and non-cacheable fragments of a web page. An "ESI aware server", such as Oracle Web Cache and Akamai EdgeSuite, can take in ESI marked content and cache and assemble pages closer to the users, at the edge of the network, rather than at the application server level. This session will discuss the challenge many dynamic websites face today, discuss what ESI is, explain how ESI can be used to alleviate these issues. The session will also describe how to build pages with ESI, and detail the ESI and JESI (Edge Side Includes for Java) libraries. </abstract> <track> Fast Track to Oracle9i </track> </paper>'));
Create an Oracle Text index on the XMLType column, papers, using the usual CREATE INDEX statement:
CREATE INDEX proc_idx ON Proceedings(papers) INDEXTYPE IS ctxsys.context parameters('FILTER ctxsys.null_filter SECTION GROUP ctxsys.path_section_group');
Oracle9i Release 1 (9.0.1) introduced two new SQL functions existsNode() and extract() that operate on XMLType values as follows:
existsNode(): given an XPath expression, checks if the XPath applied over the XML document can return any valid nodes.extract(): given an XPath expression, applies the XPath to the XML document and returns the fragment as an XMLType.For example, select the authors only from the XML document:
SELECT p.papers.extract('/paper/authors/text()').getStringVal() FROM Proceedings p;
You can use the Oracle Text CONTAINS() operator to search for content in a text or XML document. For example, to search for papers that contain "Dynamic" in the title you can use:
SELECT tk FROM Proceedings WHERE CONTAINS(papers,'Dynamic INPATH(paper/title)')>0
Using the CONTAINS() operator Oracle9i returns the columns selected. For an XML document it returns the entire document. To extract fragments of XML, you can combine the extract() function to manipulate the XML. For example, select the authors of papers that contain "Dynamic" in the title:
SELECT p.papers.extract('/paper/authors/text()').getStringVal() FROM Proceedings p WHERE CONTAINS(papers,'Dynamic INPATH(paper/title)')>0
You can use all the functionality of an Oracle Text query for the content search. The following example selects the authors of papers containing "Dynamic" or "Edge" or "Libraries" in the title:
SELECT p.papers.extract('/paper/authors/text()').getStringVal() FROM Proceedings p WHERE CONTAINS(papers,'Dynamic or Edge or Libraries INPATH(paper/title)')>0
Traditional databases allow searching of XML content or structure, but not both at the same time. Oracle provides unique features that enable querying of both XML content and structure at the same time.
Figure 7-1 illustrates entering the search for "Libraries" in the structure of the Conference Proceedings documents. You can search for "Libraries" within Authors, abstract, title, company, or track. In this example, you are searching for the term "Libraries" in the abstracts only. Since it is an XML document your are searching, you can even select which fragment of the XML document you want to display. This example only displays the title of the paper.
Figure 7-2 shows the search results.
For the .jsp code to build this look-up application, see "Searching Conference Proceedings Example: jsp" .
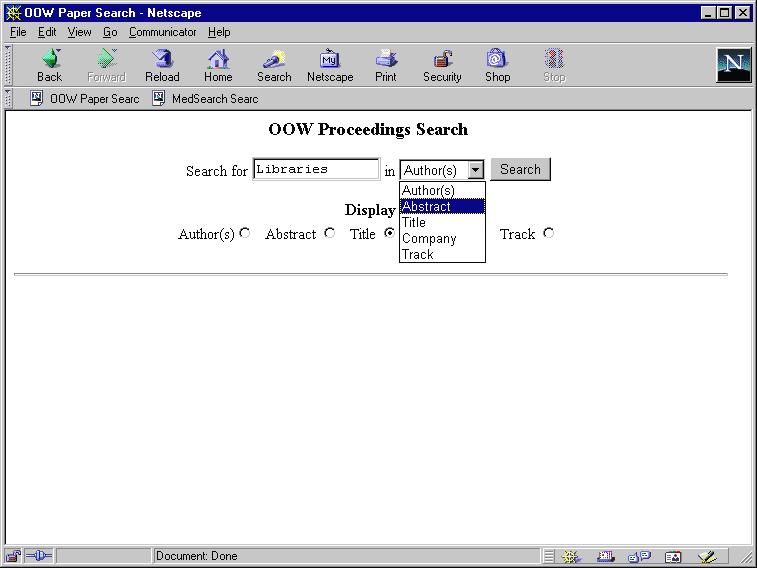
Text description of the illustration text92_01.jpg
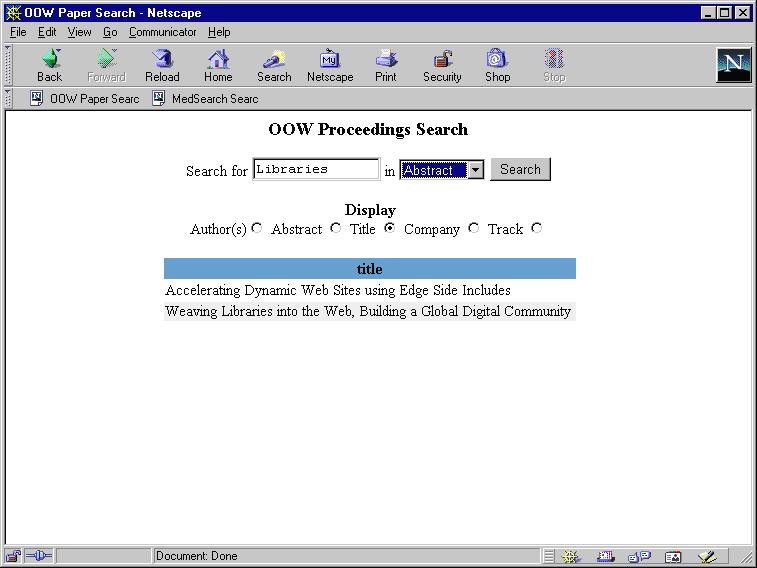
Text description of the illustration text92_02.jpg
Here is the full jsp example illustrating how you can use Oracle Text to create an online XML-based Conference Proceedings look-up application.
<%@ page import="java.sql.* , oracle.jsp.dbutil.*" %> <jsp:useBean id="name" class="oracle.jsp.jml.JmlString" scope="request" > <jsp:setProperty name="name" property="value" param="query" /> </jsp:useBean> <% String connStr="jdbc:oracle:thin:@oalonso-sun:1521:betadev"; java.util.Properties info = new java.util.Properties(); Connection conn = null; ResultSet rset = null; Statement stmt = null; if (name.isEmpty()) { %> <html> <title>OOW Paper Search</title> <body> <center> <h3>OOW Proceedings Search </h3> <form method=post> Search for <input type=text size=15 maxlength=25 name=query> in <select name="tagvalue"> <option value="authors">Author(s) <option value="abstract">Abstract <option value="title">Title <option value="company">Company <option value="track">Track </select> <input type=submit value="Search"> <p><b>Display</b><br> <table> <tr> <td> Author(s)<input type="radio" name="section" value="authors"> </td> <td> Abstract <input type="radio" name="section" value="abstract"> </td> <td> Title <input type="radio" name="section" value="title" checked> </td> <td> Company <input type="radio" name="section" value="company"> </td> <td> Track <input type="radio" name="section" value="track"> </td> </tr> </table> </form> </center> <hr> </body> </html> <% } else { %> <html> <title>OOW Paper Search</title> <body> <center> <h3>OOW Proceedings Search </h3> <form method=post action="oowpapersearch.jsp"> Search for <input type=text size=15 maxlength=25 name="query" value=<%= name.getValue() %>> in <select name="tagvalue"> <option value="authors">Author(s) <option value="abstract">Abstract <option value="title">Title <option value="company">Company <option value="track">Track </select> <input type=submit value="Search"> <p><b>Display</b><br> Author(s)<input type="radio" name="section" value="authors"> Abstract <input type="radio" name="section" value="abstract"> Title <input type="radio" name="section" value="title" checked> Company <input type="radio" name="section" value="company"> Track <input type="radio" name="section" value="track"> </form> </center> <% try { DriverManager.registerDriver(new oracle.jdbc.driver.OracleDriver() ); info.put ("user", "ctxdemo"); info.put ("password","ctxdemo"); conn = DriverManager.getConnection(connStr,info); stmt = conn.createStatement(); String theQuery = request.getParameter("query")+" INPATH(paper/"+request.getParameter("tagvalue")+")"; String tagValue = request.getParameter("tagvalue"); String sectionValue = request.getParameter("section"); // select p.papers.extract('/paper/authors').getStringVal() // from oowpapers p // where contains(papers,'language inpath(paper/abstract)')>0 String myQuery = "select p.papers.extract('/paper/"+request.getParameter("section")+"/text()').getStringV al() from oowpapers p where contains(papers,'"+theQuery+"')>0"; rset = stmt.executeQuery(myQuery); String color = "ffffff"; String myDesc = null; int items = 0; while (rset.next()) { myDesc = (String)rset.getString(1); items++; if (items == 1) { %> <center> <table border="0"> <tr bgcolor="#6699CC"> <th><%= sectionValue %></th> </tr> <% } %> <tr bgcolor="#<%= color %>"> <td> <%= myDesc %></td> </tr> <% if (color.compareTo("ffffff") == 0) color = "eeeeee"; else color = "ffffff"; } } catch (SQLException e) { %> <b>Error: </b> <%= e %><p> <% } finally { if (conn != null) conn.close(); if (stmt != null) stmt.close(); if (rset != null) rset.close(); } %> </table> </center> </body></html> <% } %>
This Frequently Asked Questions (FAQs) section is divided into the following categories:
Answer: Yes you can. See "Querying XML Data: Use CONTAINS or existsNode()?".
I know that an intact XML document can be stored in a CLOB in Oracle's XML solution.
Can XML documents stored in a CLOB or a BLOB be queried like table schema? For example:
[XML document stored in BLOB]...<name id="1111"><first>lee</first> <sencond>jumee</second></name>...
Can value (lee, jumee) be queried by elements, attributes, and the structure of XML document?
Answer: Using Oracle Text, you can find this document with a queries such as:
lee within first jumee within second 1111 within name@id
You can combine these like this:
lee within first and jumee within second, or (lee within first) within name.
For more information, please read the Oracle Text Technical Overview available on OTN at http://otn.oracle.com/products/text
If some element or attribute is inserted, updated, or deleted, must the whole document be updated? Or can insert, update, and delete function as in table schema?
Answer: Oracle Text indexes CLOB and BLOB, and this has no knowledge about XML specifically, so you cannot really change individual elements. You have to edit the document as a whole.
About locking, if we manage an XML document stored in a CLOB or a BLOB, can anyone access the same XML document?
Answer: Just like any other CLOB, if someone is writing to the CLOB, they have it locked and nobody else can write to the CLOB. Other users can read it, but not write to it. This is basic LOB behavior.
An alternative is to decompose the XML document and store the information in relational fields. Then you can modify individual elements, have element-level simultaneous access, and so on. In this case, using something called the USER_DATASTORE and PL/SQL, you can reconstitute the document to XML for text indexing. Then, you can search the text as if it were XML, but manage the data as if it were relational data. Again, see the Oracle Text Technical Overview for more information at: http://otn.oracle.com/products/text.
I need to store a large XML file, search it, and return a specific tagged area. Using Oracle Text some of this is possible:
CLOB fieldctxsys.context<Zones> and <Fields> to represent the tags in my XML file Ex. ctx_ddl.add_zone_section(xmlgroup,"dublincore", dc);fieldEx. Select title from mytable where CONTAINS(textField,"some words WITHIN doubleness")How do I return a zone or a field based on a text search?
Answer: Oracle Text will only return the "hits". You can use Oracle Text doc service to highlight or mark up the section, or you can store the CLOB in an XMLType column and use the extract() function.
How do I insert XML documents into a database? I need to insert the XML document as-is in column of datatype CLOB into a table.
Answer: Oracle's XML SQL Utility for Java offers a command-line utility that can be used for loading XML data. More information can be found on the XML SQL Utility at the following Web site:
http://otn.oracle.com/tech/xml
as well as in Chapter 7, "XML SQL Utility (XSU)".
You can insert the XML documents as you would any text file. There is nothing special about an XML-formatted file from a CLOB perspective.
Can Oracle Text be used to index and search XML stored in CLOBs? How can we get started?
Answer: Versions of Oracle Text before Oracle8i Release 2 (8.1.6) only allowed tag-based searching. The current version allows for XML structure and attribute based searching. There is documentation on how to have the index built and the SQL usage in the Oracle Text documentation.
I have this XML code:
<person> <name>efrat</name> <childrens> <child> <id>1</id> <name>keren</name> </child> </childrens> </person>
How do I find the person who has a child name keren but not the person's name keren? This assumes I defined every tag with the add_zone_section that can be nested and can include themselves.
Answer: Use '(keren within name) within child'.
Answer: See the following manuals:
Can Oracle Text recognize the tags in my XML document or do I have to use the add_field_section command for each tag in the XML document? My XML documents have hundreds of tags. Is there an easy way to do this?
Answer: Which version of the database are you using? I believe you need to use that command for Oracle8 release 8.1.5 but not in Oracle8i release 2 (8.1.6). You can use AUTO_SECTION_GROUP in Oracle8i release 2 (8.1.6).
XSQL Servlet ships with a complete (albeit simple from the Oracle Text standpoint) example of a SQL script that creates a complex XML datagram out of object types, and then creates an Oracle Text index on the XML document fragment stored in the Insurance Claim type.
If you download the XSQL Servlet, and look at the file ./xsql/demo/insclaim.sql you'll be able to see the Oracle Text stuff at the bottom of the file. One of the key new features in Oracle Text in Oracle8i release 2 (8.1.6) was the AUTO Section for XML.
I have an XML document that I have stored in CLOB. I have also created the indexes on the tags using section_group, and so on. One of the tags is <SALARY> </SALARY>. I want to write a SQL statement to select all the records that have salary of greater than 5000. How do I do this? I cannot use the WITHIN operator. I want to interpret the value present in this tag as a number. This could be a floating point number also since this is salary.
Answer: You cannot do this in Oracle Text. Range search is not really a text operation. The best solution is to use the other Oracle XML parsing utilities to extract the salary into a NUMBER field. Then, you can use Oracle Text for text searching, and normal SQL operators for the more structured fields, and achieve the same results.
We are storing all our documents in XML format in a CLOB. Are there utilities available in Oracle, perhaps Oracle Text, to retrieve the contents a field at a time? That is, given a field name, can I get the text between tags, as opposed to retrieving the whole document and traversing the structure?
Answer: Oracle Text does not do section extraction. See the XML SQL Utility for this.
I have created a view based on seven to eight tables and it has columns like custordnumber, product_dsc, qty, prdid, shipdate, ship_status, and so on. I need to create an Oracle Text index on the three columns:
Is there a way to create a Text index on these columns?
Answer: The short answer is yes. You have two options:
USER_DATASTORE object to create a concatenated field on the fly during indexing; orCLOB field in one of your tables. Then, create the index on the CLOB field. If you're using Oracle8i release 2 (8.1.6) or higher, then you also have the option of placing XML tags around each field prior to concatenation. This gives you the capability of searching within each field.We are using mySQL to do partial indexing of 9 million Web pages a day. We are running on a 4-processor Sparc 420 and are unable to do full text indexing. Can Oracle8i or Oracle9i do this?
We are not interested in transactional integrity, applying any special filters to the text pages, or in doing any other searching other than straight boolean word searches (no scoring, no stemming, no fuzzy searches, no proximity searches, and so on).
I have are the following questions:
Answer: Yes. Oracle Text can create a full-text index on 9 million Web pages - and pretty quickly. In a benchmark on a large Sun box, we indexed 100 GB of Web pages (about 15 million) in 7 hours. We can also do partial indexing through regular DML or (in Oracle9i) through partitioning.
You can do "indexing lite" to some extent by disabling theme indexing. You do not need to filter documents if they are already in ASCII, HTML, or XML, and most common expansions, like fuzzy, stemming, and proximity, are done at query time.
Currently Oracle Text has the option to create indexes based on the content of a section group. But most XML elements are of the type Element. So, the only option for searching would be attribute values. Can I build indexes on attribute values?
Answer: Oracle8 release 8.1.6 and higher allow attribute indexing. See the following site:
http://otn.oracle.com/products/intermedia/htdocs/text_training_816/Samples/imt_816_techover.html#SCN
I store XML in CLOBs and use the DOM or SAX parsers to reparse the XML later as needed. How can I search this document repository? Oracle Text seems ideal. Do you have an example of setting this up using interMedia in Oracle8i, demonstrating how to define the XML_SECTION_GROUP and where to use a ZONE as opposed to a FIELD, and so on? For example:
How would I define interMedia parameters so that I would be able to search my CLOB column for records that had the values aorta and damage using the following XML (the DTD of which is implied)
WellKnownFileName.gif <keyword>echo</keyword> <keyword>cardiogram aorta</keyword>
This is an image of the vessel damage.
Answer: Oracle8i release 2 (8.1.6) and higher allow searching within attribute text. That's something like: state within book@author. Oracle now offers attribute value sensitive search, more like the following:
state within book[@author = "Eric"]:
begin ctx_ddl.create_section_group('mygrp','basic_section_group');
ctx_ddl.add_field_section('mygrp','keyword','keyword');
ctx_ddl.add_field_section('mygrp','caption','caption');
end;
create index myidx on mytab(mytxtcolumn)indextype is ctxsys.contextparameters
('section group mygrp');
select * from mytab where contains(mytxtcolumn, 'aorta within keyword')>0;
options:
keywords is a field section, then (aorta and echo cardiogram) within keywords finds the document. If it is a zone section, then it does not, because they are not in the SAME instance of keywords.I need to store XML files, which are currently on the file system, in the database. I want to store them as whole documents; that is, I do not want to break the document down by tags and then store the info in separate tables or fields. Rather, I want to have a universal table, that I can use to store different XML documents. I think internally it will be stored in a CLOB type of field. My XML files will always contain ASCII data.
Can this be done using Oracle Text? Should we be using Oracle Text or Oracle Text Annotator for this? I downloaded Annotator from OTN, but I could not store XML documents in the database.
I am trying to store XML documents in a CLOB column. Basically I have one table with the following definition:
CREATE TABLE xml_store_testing ( xml_doc_id NUMBER, xml_doc CLOB )
I want to store my XML document in an xml_doc field.
I have written the following PL/SQL procedure, to read the contents of the XML document. The XML document is available on the file system and contains just ASCII data, no binary data.
CREATE OR REPLACE PROCEDURE FileExec ( p_Directory IN VARCHAR2, p_FileName IN VARCHAR2) AS v_CLOBLocator CLOB; v_FileLocator BFILE; BEGIN SELECT xml_doc INTO v_CLOBLocator FROM xml_store_testing WHERE xml_doc_id = 1 FOR UPDATE; v_FileLocator := BFILENAME(p_Directory, p_FileName); DBMS_LOB.FILEOPEN(v_FileLocator, DBMS_LOB.FILE_READONLY); dbms_output.put_line(to_char(DBMS_LOB.GETLENGTH(v_FileLocator))); DBMS_LOB.LOADFROMFILE(v_CLOBLocator, v_FileLocator, DBMS_LOB.GETLENGTH(v_FileLocator)); DBMS_LOB.FILECLOSE(v_FileLocator); END FileExec;
Answer: Put the XML documents into your CLOB column, then add an Oracle Text index on it using the XML_SECTION_GROUP. See the documentation and overview material at this Web site: http://otn.oracle.com/products/intermedia.
When I put my XML documents in a CLOB column, then add an Oracle Text index using the XML section-group, it executes successfully. But when I select from the table I see unknown characters in the table in CLOB field. Could this be because of the character set difference between operating system, where XML file resides, and database, where CLOB data resides?
Answer: Yes. If the character sets are different then you probably have to pass the data through UTL_RAW.CONVERT to do a character set conversion before writing to the CLOB.
I need to insert data in the database from an XML file. Currently I can only insert structured data with the table already created. Is this correct?
I am working in a law project where we need to store laws containing structured data and unstructured data, and then search the data using Oracle Text. Can I insert unstructured data too? Or do I need to develop a custom application to do it? Then, if I have the data stored with some structured parts and some unstructured parts, can I use Oracle Text to search it? If I stored the unstructured part in a CLOB, and the CLOB has tags, how can I search only data in a specific tag?
Answer: Consider usingOracle9iFS, which enables you to break up a document and store it across tables and in a LOB. Oracle Text can perform data searches with tags and is knowledgeable about the hierarchical XML structure. From Oracle8i release 2 (8.1.6), Oracle Text has had this capability, along with name/value pair attribute searches.
Is document breaking possible if I don't create a custom development? Although Oracle Text does not understand hierarchical XML structure, can I do something like this?
<report> <day>yesterday</day> there was a disaster <cause>hurricane</cause> </report>
Indexing with Oracle Text, I would like to search LOBs where cause was hurricane. Is this possible?
Answer: You can perform that level of searching with the current release of Oracle Text. Currently, to break a document up you have to use the XML Parser with XSLT to create a style sheet that transforms the XML into DDL. Oracle9iFS gives you a higher level interface.
Another technique is to use a JDBC program to insert the text of the document or document fragment into a CLOB or LONG column, then do the searching using the CONTAINS() operator after setting up the indexes.
I have a CLOB column that has an existing XML_SECTION_GROUP index on certain tags within the XML content of the CLOB, as follows:
begin ctx_ddl.create_section_group('XMLDOC','XML_SECTION_GROUP'); end; / begin ctx_ddl.add_zone_section ('XMLDOC','title','title'); ctx_ddl.add_zone_section('XMLDOC','keywords','keywords'); ctx_ddl.add_zone_section('XMLDOC','author','author'); end; / create index xmldoc_idx on xml_documents(xmldoc) indextype is ctxsys.context parameters ('section group xmldoc') ;
I need to search on the 'author' zone section by the first letter only. I believe I should use a substring index but I am unsure of the syntax to create a substring index. Especially when I have already declared a SECTION_GROUP preference on this column and I would also need to create a WORDLIST preference.
Answer. The main problem here is that you cannot apply that fancy substring processing just to the author section. It will apply to everything, which will probably blow up the index size. Anything you do will require reindexing the documents, so you cannot really get around having to rebuild the index entirely. Here are various ways to solve your problem:
WITHIN AUTHOR
Pro: You do not have to rebuild the index.
Con: The query is slow. Some queries cannot be executed due to wildcard maxterms limits.
WITHIN AUTHOR
Pro: This is a moderately fast query.
Con: You must use Oracle8i Release 3 (8.1.7) or higher or you will get 'junk' from words from other sections.
Pro: This faster query than 2.
Con: The field sections are less flexible with regards to. nesting and repeating occurrences.
<AUTHOR>Steven King</AUTHOR>
becomes
<AUTHORINIT>AIK</AUTHORINIT><AUTHOR>Steven King<AUTHOR>
Use field section for AUTHORINIT and query becomes:
AIK within AUTHORINIT
I used AIK instead of just K so that you do not have to make I and A non-stopwords.
Pro: This is the fastest query and the smallest index.
Con: It involves the most work as you have to massage the data so it slows down indexing.
We are using Sun SPARC Solaris 5.8, Oracle8i Enterprise Edition Release 3 (8.1.7.2.0), Oracle Text. We are indexing XML documents that contain attributes within the XML tags. One of the sections in the XML is a list of subjects associated with the document. Each subject has a relevance associated with it. We want to search for topic x with relevance y but we get the wrong results. For example: The data in some of the rows look like this, considering subject PA:
DOC 1 --> Story_seq_num = 561106 <ne-metadata.subjectlist> <ne-subject code="PA" source="NEWZ" relevance="50" confidence="100"/> <ne-subject code="CONW" source="NEWZ" relevance="100" confidence="100"/> <ne-subject code="LENF" source="NEWZ" relevance="100" confidence="100"/> <ne-subject code="TRAN" source="NEWZ" relevance="100" confidence="100"/> </ne-metadata.subjectlist> DOC 2 --> Story_seq_num =561107 <ne-metadata.subjectlist> <ne-subject code="CONW" source="NEWZ" relevance="100" confidence="100"/> ...
If users wants subject PA with relevance = 100, only DOC 2 should be returned. Here is a test case showing the results:
Are these the expected results?
TABLE
drop table t_stories1 ; create table t_stories1 as select * from t_Stories_bck where story_Seq_num in (561114,562571,562572,561106,561107);
INDEX SECTIONS
BEGIN -- Drop the preference if it already exists CTX_DDL.DROP_SECTION_GROUP('sg_nitf_story_body2'); END; / BEGIN --Define a section group ctx_ddl.create_section_group ('sg_nitf_story_body2','xml_section_group'); -- Create field sections for headline and body ctx_ddl.add_field_section('sg_nitf_story_body2','HL','hedline',true); ctx_ddl.add_field_section('sg_nitf_story_body2','ST','body.content', true); --Define attribute sections for the source fields ctx_ddl.add_attr_section( 'sg_nitf_story_body2', 'P', 'ne-provider@id'); ctx_ddl.add_attr_section( 'sg_nitf_story_body2', 'C', 'ne-publication@id'); ctx_ddl.add_attr_section( 'sg_nitf_story_body2', 'S', 'ne-publication@section'); ctx_ddl.add_attr_section( 'sg_nitf_story_body2', 'D', 'date.issue@norm'); ctx_ddl.add_attr_section( 'sg_nitf_story_body2', 'SJ', 'ne-subject@code'); ctx_ddl.add_attr_section( 'sg_nitf_story_body2', 'SJR', 'ne-subject@relevance'); ctx_ddl.add_attr_section( 'sg_nitf_story_body2', 'CO', 'ne-company@code'); ctx_ddl.add_attr_section( 'sg_nitf_story_body2', 'TO', 'ne-topic@code'); ctx_ddl.add_attr_section( 'sg_nitf_story_body2', 'TK', 'ne-orgid@value'); ENd; /
creating the index
drop index ix_stories ; CREATE INDEX ix_stories on T_STORIES1(STORY_BODY) INDEXTYPE IS CTXSYS.CONTEXT PARAMETERS ('SECTION GROUP sg_nitf_story_body2 STORAGE ixst_story_body ');
-- testing the index
--We are looking for the subject PA with relevance = 100
--query that gives us the correct results
SELECT STORY_SEQ_NUM, STORY_BODY FROM T_STORIES1 WHERE CONTAINS(STORY_BODY, 'PA WITHIN SJ')>0;
--Query that gives us the wrong results
SELECT STORY_SEQ_NUM, STORY_BODY FROM T_STORIES1 WHERE CONTAINS(STORY_BODY, 'PA WITHIN SJ AND 100 within SJR')>0;
The data in some of the rows look like this:
Story_seq_num = 561106 <ne-metadata.subjectlist> <ne-subject code="PA" source="NEWZ" relevance="50" confidence="100"/> <ne-subject code="CONW" source="NEWZ" relevance="100" confidence="100"/> <ne-subject code="LENF" source="NEWZ" relevance="100" confidence="100"/>
<ne-subject code="TRAN" source="NEWZ" relevance="100" confidence="100"/>
</ne-metadata.subjectlist> Story_seq_num =561107 <ne-metadata.subjectlist> <ne-subject code="CONW" source="NEWZ" relevance="100" confidence="100"/>
...
We are looking for the subject PA with relevance = 100
Only Story_seq_num = 561107 should be returned
The results are wrong because we wanted the subjects PA that have relevance =100. We get back story_seq_num=561106 that has relevance = 50 <ne-subject code="PA" source="NEWZ" relevance="50" confidence="100"/>
SQL> connect sosa/sosa Connected. SQL> select object_name, object_type from user_objects; OBJECT_NAME -------------------------------------------------------------------------------- OBJECT_TYPE ------------------ IX_STORIES INDEX SYS_LOB0000025364C00005$$ LOB SYS_LOB0000025364C00009$$ LOB OBJECT_NAME -------------------------------------------------------------------------------- OBJECT_TYPE ------------------ SYS_LOB0000025364C00014$$ LOB SYS_LOB0000025364C00016$$ LOB T_STORIES1 TABLE
6 rows selected.
SQL> drop index ix_stories force;
Index dropped....
Answer. Oracle8i Release 3(8.1.7) is not able to this kind of search. You need the PATH section group in Oracle9i Release 1 (9.0.1), which has a much more sophisticated understanding of such relationships. To do this in 8.1.7 you would have to re-format the documents (possibly through a procedure filter or user datastore), use zone sections, and nested withins, so that:
<A B="C" D="E">...
became
<A><B>C</B><D>E</D>...
and queries are like:
(C within B and E within D) within A in 9.0.1, you should be able to use PATH_SECTION_GROUP on the unmodified data, with a query like:
haspath(//ne-subject[@code = "PA" and @relevance = "100"])
|
 Copyright © 2002 Oracle Corporation. All Rights Reserved. |
|

