| Oracle9i SQL Reference Release 2 (9.2) Part Number A96540-02 |
|





|
View PDF |
| Oracle9i SQL Reference Release 2 (9.2) Part Number A96540-02 |
|
|
View PDF |
Oracle recognizes objects that are associated with a particular schema and objects that are not associated with a particular schema, as described in the sections that follow.
A schema is a collection of logical structures of data, or schema objects. A schema is owned by a database user and has the same name as that user. Each user owns a single schema. Schema objects can be created and manipulated with SQL and include the following types of objects:
Other types of objects are also stored in the database and can be created and manipulated with SQL but are not contained in a schema:
PFILEs) and server parameter files (SPFILEs)In this reference, each type of object is briefly defined in Chapter 9 through Chapter 18, in the section describing the statement that creates the database object. These statements begin with the keyword CREATE. For example, for the definition of a cluster, see CREATE CLUSTER.
| See Also:
Oracle9i Database Concepts for an overview of database objects |
You must provide names for most types of database objects when you create them. These names must follow the rules listed in the following sections.
Some schema objects are made up of parts that you can or must name, such as:
Tables and indexes can be partitioned. When partitioned, these schema objects consist of a number of parts called partitions, all of which have the same logical attributes. For example, all partitions in a table share the same column and constraint definitions, and all partitions in an index share the same index columns.
When you partition a table or index using the range method, you specify a maximum value for the partitioning key column(s) for each partition. When you partition a table or index using the list method, you specify actual values for the partitioning key column(s) for each partition. When you partition a table or index using the hash method, you instruct Oracle to distribute the rows of the table into partitions based on a system-defined hash function on the partitioning key column(s). When you partition a table or index using the composite-partitioning method, you specify ranges for the partitions, and Oracle distributes the rows in each partition into one or more hash subpartitions based on a hash function. Each subpartition of a table or index partitioned using the composite method has the same logical attributes.
Partition-extended and subpartition-extended names let you perform some partition-level and subpartition-level operations, such as deleting all rows from a partition or subpartition, on only one partition or subpartition. Without extended names, such operations would require that you specify a predicate (WHERE clause). For range- and list-partitioned tables, trying to phrase a partition-level operation with a predicate can be cumbersome, especially when the range partitioning key uses more than one column. For hash partitions and subpartitions, using a predicate is more difficult still, because these partitions and subpartitions are based on a system-defined hash function.
Partition-extended names let you use partitions as if they were tables. An advantage of this method, which is most useful for range-partitioned tables, is that you can build partition-level access control mechanisms by granting (or revoking) privileges on these views to (or from) other users or roles.To use a partition as a table, create a view by selecting data from a single partition, and then use the view as a table.
You can specify partition-extended or subpartition-extended table names for the following DML statements:
DELETEINSERTLOCK TABLESELECTUPDATE
|
Note: For application portability and ANSI syntax compliance, Oracle strongly recommends that you use views to insulate applications from this Oracle proprietary extension. |
The basic syntax for using partition-extended and subpartition-extended table names is:
partition_extended_name::=
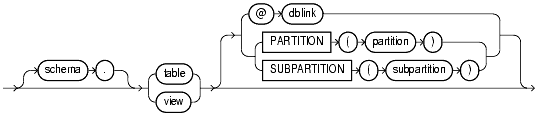
Currently, the use of partition-extended and subpartition-extended table names has the following restrictions:
In the following statement, sales is a partitioned table with partition sales_q1_2000. You can create a view of the single partition sales_q1_2000, and then use it as if it were a table. This example deletes rows from the partition.
CREATE VIEW Q1_2000_sales AS SELECT * FROM sales PARTITION (SALES_Q1_2000); DELETE FROM Q1_2000_sales WHERE amount_sold < 0;
|
 Copyright © 2000, 2002 Oracle Corporation. All Rights Reserved. |
|

